参考
李沐:Transformer论文逐段精读【论文精读】https://www.bilibili.com/video/BV1pu411o7BE/
李宏毅:台大李宏毅自注意力机制和Transformer详解 https://www.bilibili.com/video/BV1v3411r78R/
3Blue1Brown:直观解释注意力机制,Transformer的核心 https://www.bilibili.com/video/BV1TZ421j7Ke/
概览
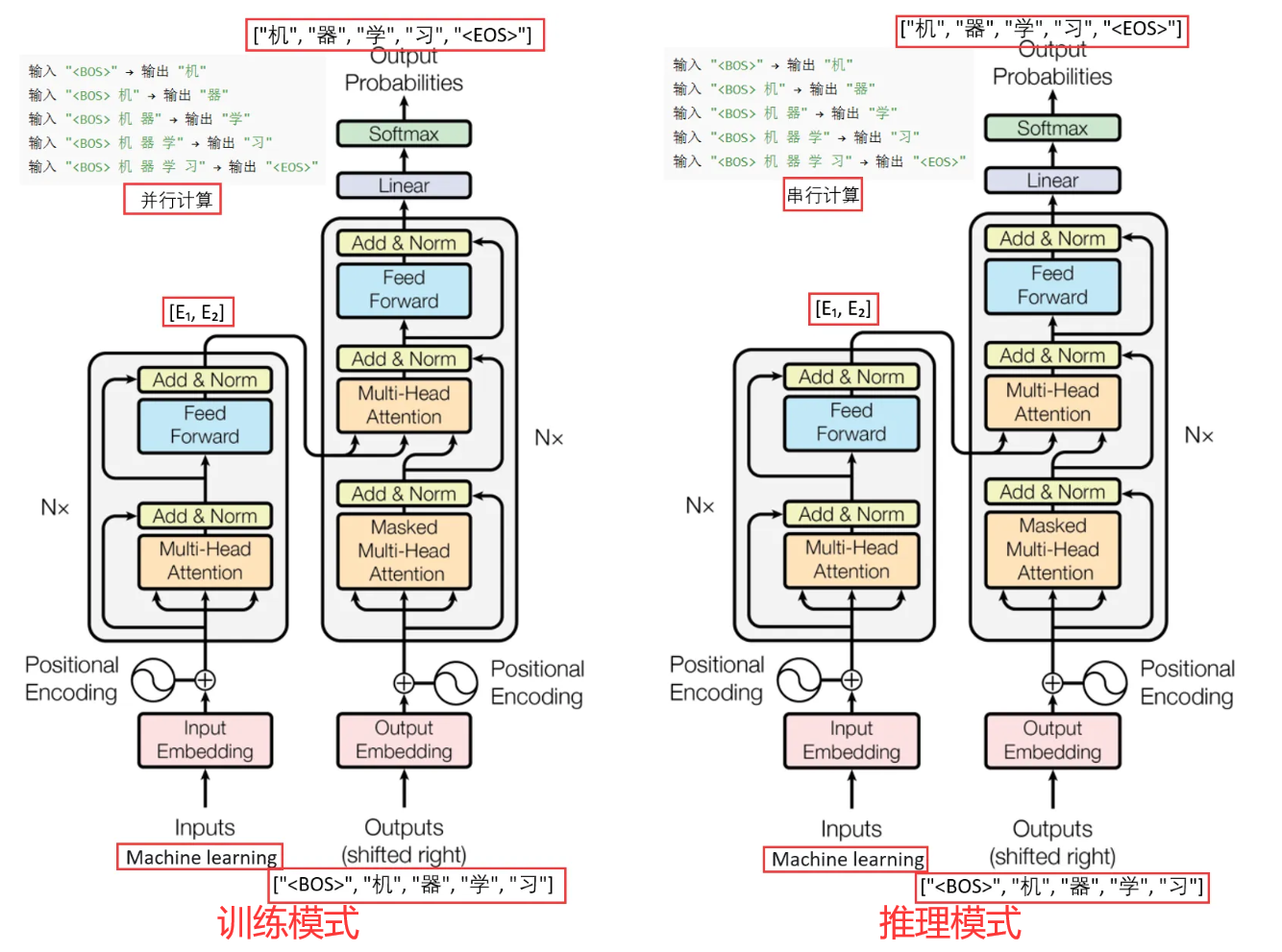
需要区分训练模式和推理(测试)模式,这可能是初学者容易混淆的地方。
训练模式
Teacher Forcing:模型采用真正的目标序列作为解码器输入,以便学习目标的条件分布。加速了训练收敛,并避免错误传播。
具体步骤:
1)解码器输入: 解码器在每个时间步使用目标序列的前一个token作为当前时间步的输入;
2)掩码机制: 使用masking确保每个时间步只能看到之前的token,而不能看到未来的token。
| 组件 | 类型 | 输入 | 输出 |
|---|---|---|---|
| Encoder | Teacher Forcing | 源序列经过词嵌入 + 位置编码 | 上下文向量 Enc_output |
| Decoder | Autoregressive | 右移一位的目标序列 | 对目标序列中每个位置的预测 |
推理模式
Autoregressive:在实际生成文本时,解码器基于已生成的token来逐步生成下一个token。解码器在每一步生成下一个token,然后将生成的token反馈到解码器的下一个时间步。
具体步骤:
1)初始输入: 解码器首先输入一个BEGIN token;
2)逐步生成: 在每个时间步生成一个token,并将这个token作为输入反馈到解码器的下一个时间步,一直到生成END token或达到最大长度。
| 组件 | 输入 | 输出 |
|---|---|---|
| Encoder(推理时只执行一次) | 源序列 | 上下文向量 Enc_output |
| Decoder(Autoregressive) | 起始符 <BOS> |
预测第一个 token |
| Decoder(后续步骤) | 上一步预测的 token 拼接到当前输入序列 | 预测下一个 token |
具体架构
本节将介绍Transformer的核心组成部分:编码器(Encoder)、解码器(Decoder)、注意力机制(Attention)、位置感知前馈神经网络、Embeddings and Softmax以及Positional Encoding。
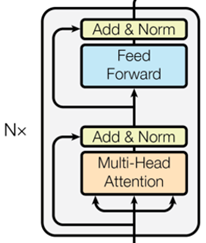
Encoder

-
论文中,设置6层Layer。
-
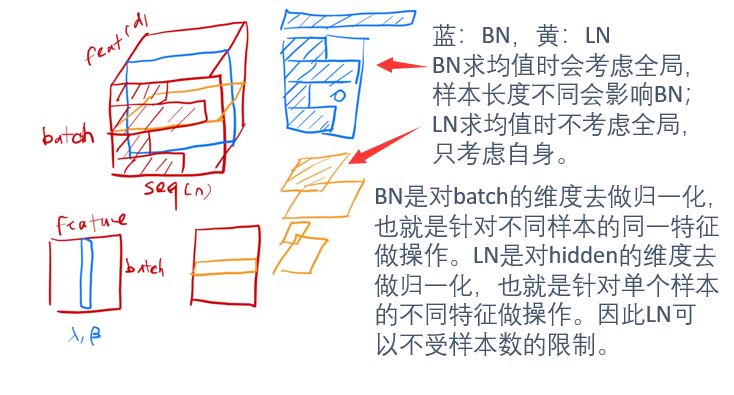
残差连接:每个sub-layer使用LayerNorm(x+Sublayer(x))
- 不是BatchNorm。
- BatchNorm会受到全局影响,而LayerNorm只考虑自身,不受全局影响。
-
每层的维度为512。
- 与维度下采样 + 通道数上升的CNN/MLP不同,这里Transformer各层维度是固定的。
-
Multi-Head Attention:见3.2节。
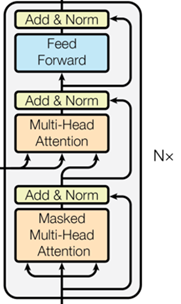
Decoder

-
论文中设置6层Layer。
-
Masked Multi-Head Attention:见3.2节。
-
Multi-Head Cross Attention:见3.2节。
Attention

- 输出维度和value维度相同。
- Compatibility function:两个词向量相似度计算
- 相似度计算有不同的方法,本论文选择了query和key的点积(Dot Product),也有其他方法如Additive Attention。
Scaled Dot-Product Attention

- Query和key在这里数量可以不一致,但是是等长的。
- 也可以不等长,有其他办法(additive attention)计算。
- Query和all keys做点积。
- 向量点积(cos),越大表示相似度越高。
- Scaled的
- 当dk很大时,点积可能过大,导致梯度很小,跑不动。
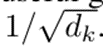
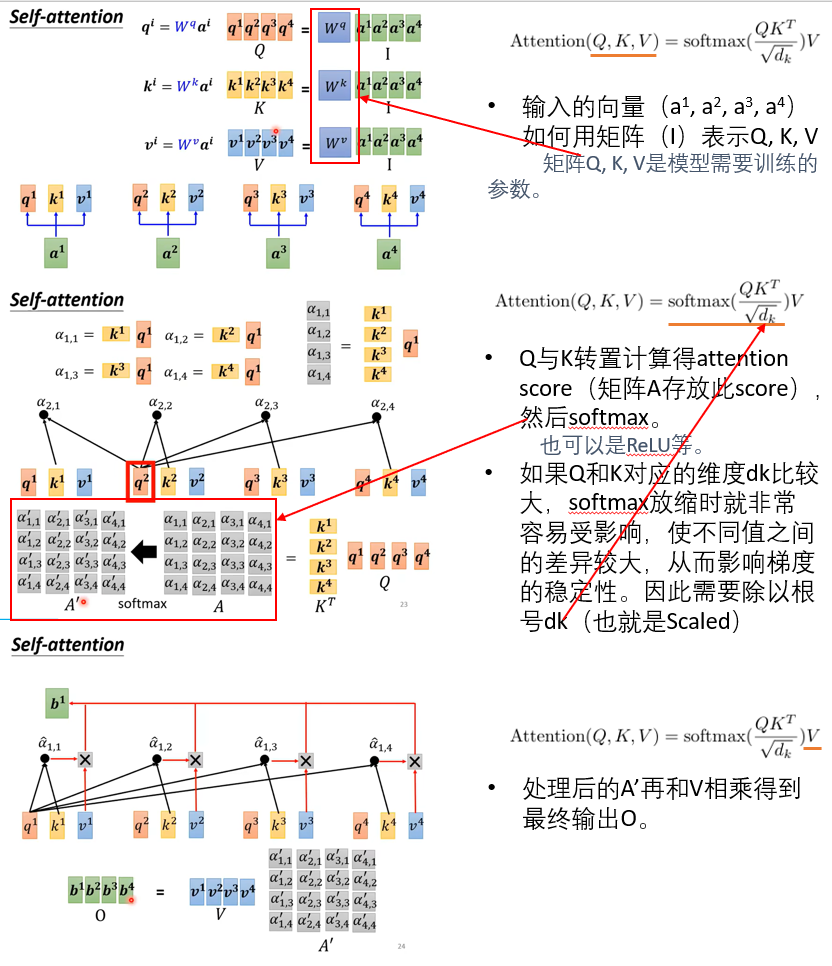
Masked Attention
- 让模型只能使用历史信息进行预测而不能看到未来信息,即不能让后词影响前词。
- 训练时,在t时刻不可看t+1, t+2…之后时刻的输入,因此需要把之后的key-value上mask(设置为趋近负无穷的负数,使得softmax后为0)。
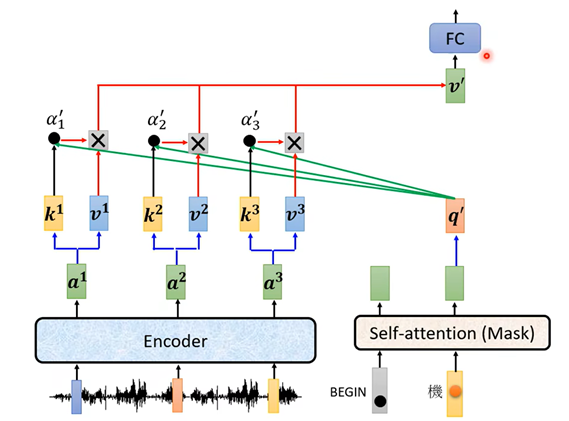
Cross Attention
- Decoder经过mask attention后得到的query,和Encoder的all key-value pairs进行计算,得到attention。
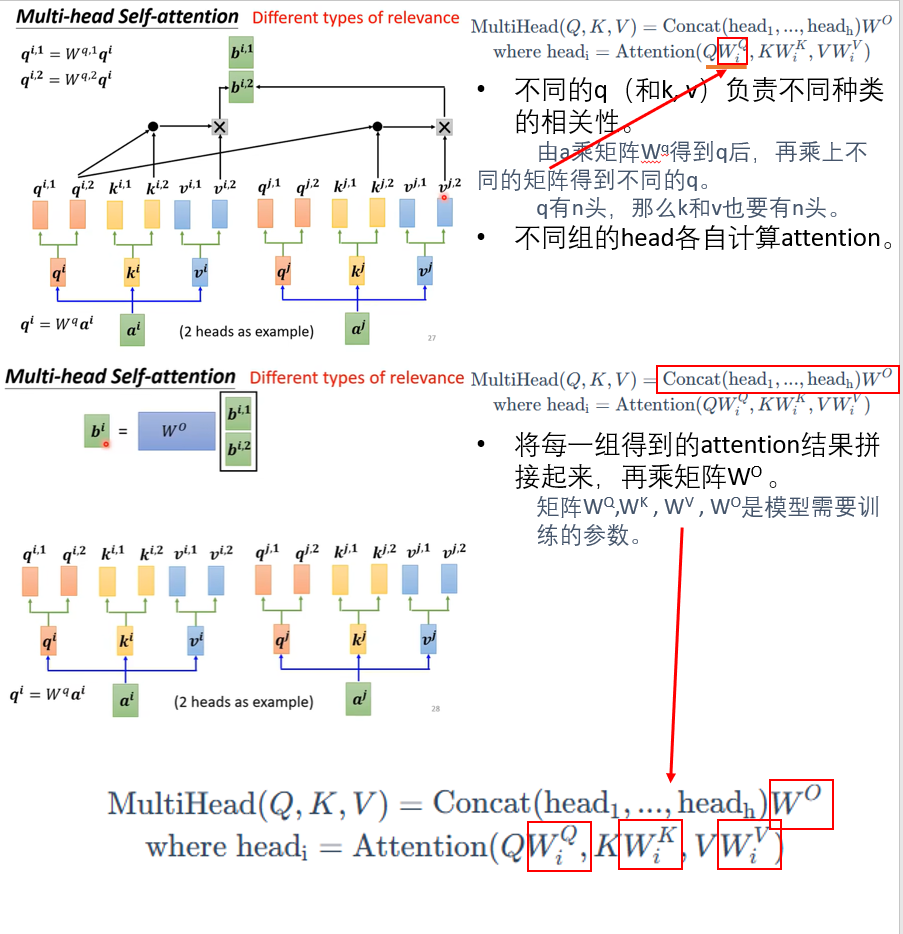
Multi-Head Attention
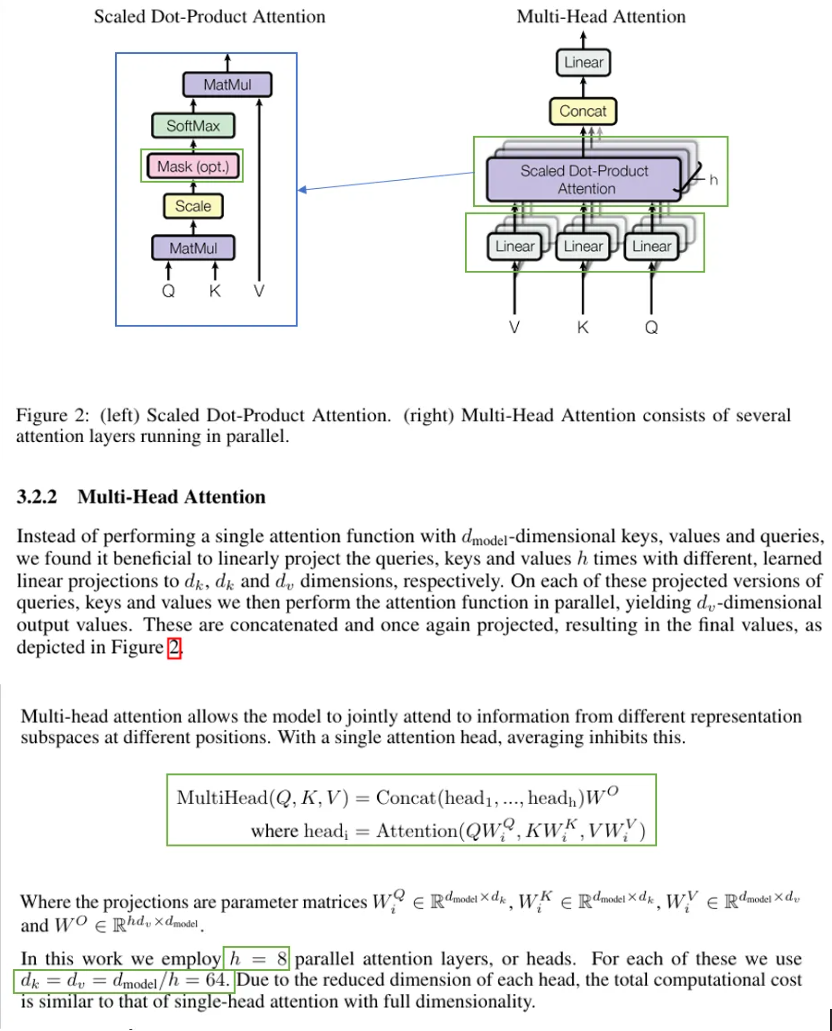
-
过程
- Linear:原始的V, K, Q进入线性层后被投影到比较低的维度。
- 点积:做h次如左图的点积注意力机制,得到h个向量并合并在一起。
- Linear:线性投影回去。
-
公式
- 原始输入Q, K, V投影到低维计算Attention得到不同的head (线性层的参数W,可学习) ,不同的head经过Concat后再做投影。
-
论文这里使用了8个head。
-
由于有残差连接,所以输入和输出的维度相同,所以投影维度为512/8=64。
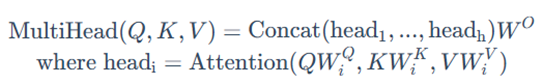
总结

| Attention应用 | 解释 | 图片 |
|---|---|---|
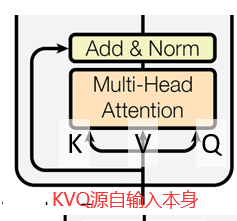
| 编码器的Multi-Head Attention | K, V, Q都源自原始输入本身(Self); 权重来源与本身与各向量之间的相似度; Multi-Head下,学习h个不同的距离空间。 |
 |
| 解码器的Masked Attention | 和上面不同之处在于,后面的向量的权要设为0。 | 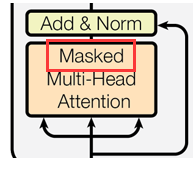 |
| 解码器的Cross Attention | K, V来自于编码器的输出,Q来自于解码器Masked Attention的输出。 eg.编码器输出'Hello', ‘world'的向量,解码器输入了'你', '好', ‘世', ‘界'的向量,那么'好'的query查询'Hello'的key-value对,相似度较高;查询'world'的相似度较低。 |
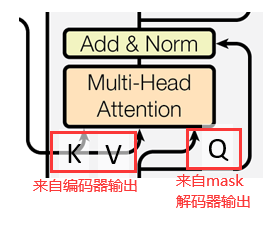 |
位置感知前馈神经网络

- Position-wise:前馈网络对每个时间步(token 位置)的向量独立地进行相同的非线性变换。
- 线性层/MLP公式:语义空间的转换
- max(0, W1 x+b1):ReLU激活层;
- W1把x从512维度扩大到2048(4倍);
- 但由于残差连接输入输出维度相同,所以又用W2把维度投回512。
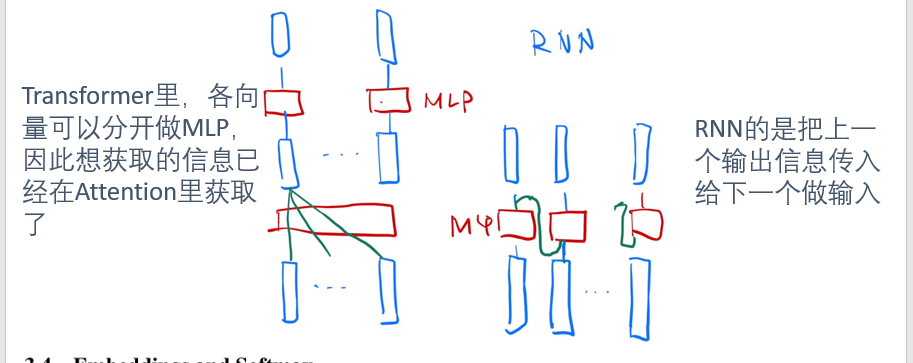
| 模型类型 | 信息流方向 | 是否共享时间步信息 | 能否并行 |
|---|---|---|---|
| RNN (Recurrent Neural Network) | 串行 (time-step by time-step) | ✅ 是,每个时刻依赖上一个隐藏状态  |
❌ 否(必须顺序计算) |
| Transformer + Position-wise FFN | 并行(所有位置同时) | ❌ 否,FFN 对每个位置独立 | ✅ 是(所有位置一起算) |
Embeddings and Softmax

- 转换权重乘根号d(d=512)
- 学embedding时,会把向量的l2norm学得较少,所以需要乘此,使得和Positional Encoding相加时scale上差不多。
Positional Encoding

-
加入时序信息
- RNN:上一个输出是下一个输入,本身就是时序的。
- Attention:本身没有时序信息,因此要在输入里额外加入。
-
如何加入
-
思想可类比计算机表示数字:假设用一个32位的整数表示数字的话,相当于用32个bit(每个bit有不同的值表示数字)。可以认为一个数是用长为32的一个向量表示。
-
回到模型,最终的输入由位置编号和embedding相加,但是embedding是长为512的向量,因此位置编号不可以只是1,2,3…的整数,所以需要将位置编号的整数展开成长为512的向量。由于一个数可以用不同周期的sin和cos表示为一个长为512的向量,所以只要将位置编号如此展开,即可相加。
-
eg 假设d=8, pos=2(即第2个token),则每维的PE值如下:
最终得到 PE(pos=2)=[0.9093,−0.4161,0.1987,0.9801,0.0200,0.9998,0.0020,0.999998]
-
-
与Mask的关系: Positional Encoding 已经告诉模型token的先后顺序,为什么还需要 mask 来防止看到后面的词?
- Positional Encoding 的作用:告诉模型位置顺序,但Attention仍然可以访问全部词的信息。
- Masked Attention 的作用:强制因果性,阻止模型用后面的信息预测前面的词。

实验

- Byte-pair encoding(BPE)
- 可以提取词根,可以让字典变得比较小。

- Warmup
- 一开始学习率非常小,慢慢升上去,当模型稳定后再逐步衰减。