Agent-Q
这篇论文的agent,不是传统的 Observation-Thinker-Actor 划分,而是 Observation-Actor(包括 Plan-Thought-Env Action-Explanation)。
模型可视为 POMDP(部分可观测马尔可夫决策过程):(O, S, A, T, R, μ₀, γ)。
Obervation(O)
- 对象:用户指令和浏览器状态(HTML DOM)。
Actor(A)
论文将计划(plan)、推理(thought)、环境动作(env action)和解释(explanation)这四个部分统一作为 composite action。训练时LLM会同时学习这四个子输出。
- MCTS 的搜索空间:只对 env action 做树状探索和评估。
- DPO 优化的数据:是基于 MCTS 轨迹得到的偏好对,但在训练时会一起优化 plan / thought / explanation,因为它们被建模为和 env action 同属于一个 composite action。
Plan
- 初始步骤的顺序执行计划。 仅在初始观察之后的第一个动作会生成。
Thought
- 在后续的每一步,模型都会生成一个类似CoT的推理步骤(
atht),这相当于一个内部的思考过程,解释了为什么选择这个动作。
Env Action
- 唯一直接与环境(浏览器)交互的部分, 包括点击网页元素(CLICK)、输入文本(TYPE)、滚动页面(SCROLL)、向用户请求信息(ASK USER)等。
Explanation
- 在执行完环境动作之后生成。给出对刚才动作的解释,用于表示 agent 的意图和当前状态。虽然不影响环境,但会影响之后的决策。
图表说明

【AI生成】图2解释
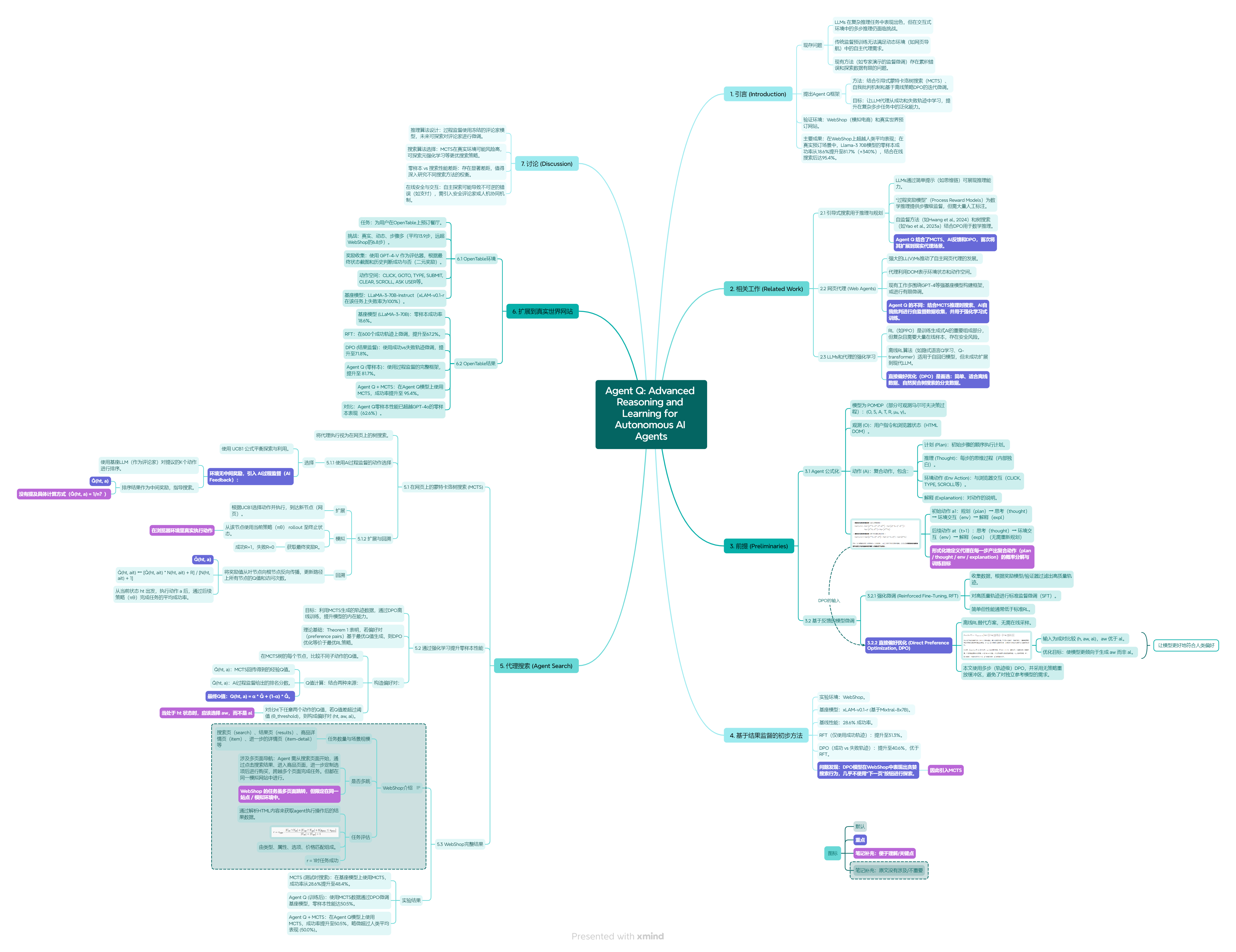
这张图是理解Agent Q智能体在推理/测试阶段(Inference Phase)如何工作的关键。它清晰地展示了智能体的“输入-输出”流程,即LLM如何根据当前环境信息进行推理并生成可执行的动作。
左侧:智能体输入 (Agent Input)
这是智能体在做出决策前接收到的所有信息。这些信息共同构成了其“上下文”或“记忆”。
<SYSTEM_PROMPT>(系统提示):
- 这是一个固定的、预先设定的指令,用于指导智能体的整体行为和角色。例如,它可能告诉模型:“你是一个专业的餐厅预订助手,需要遵循严格的步骤来完成任务。”虽然图中没有显示具体内容,但它是模型行为的基础。
<EXECUTION HISTORY>(执行历史):
- 这是智能体到目前为止已经采取的所有动作的记录。它包含了之前的状态和操作序列。
- 在图中,它被简化为一个文本块,其中包含了用户查询(USER QUERY)和当前观察(CURRENT OBSERVATION)。
- 用户查询:
Book a reservation for the restaurant Coconi's on OpenTable for 2 people on June 17 2024 at 7:00pm。这是智能体需要完成的最终目标。 - 当前观察:
CURRENT OBSERVATION:后面跟着一个网页截图。这代表了智能体当前所处的环境状态——在OpenTable网站上,位于Coconi's餐厅的页面。
CURRENT OBSERVATION:(当前观察):
- 这是智能体感知到的实时环境状态。
- 根据论文第3.1节,这个观察是以HTML DOM格式表示的。图中的截图就是DOM的一个可视化呈现。
- 它包含了所有与任务相关的视觉和交互元素,如餐厅名称、日期选择器、时间选择器、人数选择器、按钮等。智能体需要解析这个DOM来理解环境。
右侧:智能体输出 (Agent Output)
这是智能体基于输入信息进行推理后生成的响应。它是一个结构化的、复合的动作,旨在指导执行器(Executor)。
PLAN:(计划):
- 这是智能体为完成整个任务而制定的宏观策略。
- 它是一个分步列表,列出了从当前状态到最终成功所需执行的一系列主要步骤。
- 在图中,计划是:
- 选择预订日期(2024年5月22日)。
- 选择预订时间(晚上7点)。
- 选择用餐人数(4人)。
- 点击“查找餐桌”按钮完成预订。
- 这个计划是高层级的,它为后续的思考和具体动作提供了方向。
THOUGHT:(思考):
- 这是智能体在执行计划时的内部推理过程。
- 它解释了为什么选择当前的行动,以及对当前状态的理解。
- 在图中,思考是:
“我目前在OpenTable上的Coconi's餐厅页面,我需要选择预订的日期和时间,并选择用餐人数。我将专注于选择日期、时间和用餐人数。”
- 这个思考是低层级的,它聚焦于当前步骤的细节。它表明模型正在分析当前的DOM,识别出需要操作的元素(日期、时间、人数),并决定优先处理日期。
COMMANDS:(命令):
- 这是智能体生成的具体、可执行的指令,也是整个输出中最关键的部分。
- 它直接传递给执行器(Executor)去操作浏览器。
- 在图中,命令是:
CLICK <select>Date</select>
- 这个命令明确指出了要执行的操作(
CLICK)和要点击的目标(<select>Date</select>)。这里的<select>Date</select>是DOM中代表“日期选择器”的元素的HTML标签和ID(或类似标识符)。 - 执行器会解析这个命令,在浏览器中找到对应的元素并触发点击事件。
STATUS:(状态码):
- 这是一个简单的状态指示,告诉系统下一步该做什么。
- 在图中,状态码是
CONTINUE,意味着任务仍在进行中,需要继续下一个步骤。 - 其他可能的状态码可能是
SUCCESS(任务成功)、FAILURE(任务失败)或ASK_USER(需要用户介入)。
总结
图2的核心意义在于,它展示了一个结构化、可解释的AI Agent架构:
- 输入:智能体接收一个完整的上下文,包括长期目标(用户查询)、历史记录和当前环境快照(DOM)。
- 输出:智能体通过多层推理,生成一个包含计划(宏观)、思考(微观)和命令(执行)的复合输出。
- 作用:这种结构化输出使得智能体的行为变得透明和可控。研究人员可以轻松地检查每个部分(计划、思考、命令)来调试和理解模型的决策过程。同时,
COMMANDS部分确保了与真实世界的接口是标准化和可执行的。
训练阶段
MCTS(Monte Carlo Tree Search)
为什么使用MCTS
只使用DPO进行实验后发现:DPO模型在WebShop中表现出贪婪搜索行为(几乎不使用“下一页”按钮进行探索)。为此引入MCTS引导Agent进行探索,
MCTS工作原理
- 作用:在训练阶段作为“数据生成器”(每个节点计算Q值),引导Agent在环境中探索。
- 不调整参数:MCTS本身不直接更新模型参数,而是为DPO提供训练数据。
- Q值计算:
- MCTS本身的Q值更新:
- AI过程监督产生的Q值:
(文中未给出具体的计算公式)
- MCTS本身的Q值更新:


选择
- UCB1:
- UCB1平衡探索与利用。
- 最终Q值将代入UCB1公式
- 使用UCB1公式选择节点(动作)并执行,到达新节点(网页)。
- AI过程监督:
- 由于网页环境奖励稀疏,引入一个基于LLM的“批评模型”(critic)。
- 该模型对当前节点下可能的K个动作进行打分和排名,提供中间奖励(intermediate reward)。
- 解决了信用分配(credit assignment)问题,指导搜索走向更优路径。
- 生成
。


图表说明
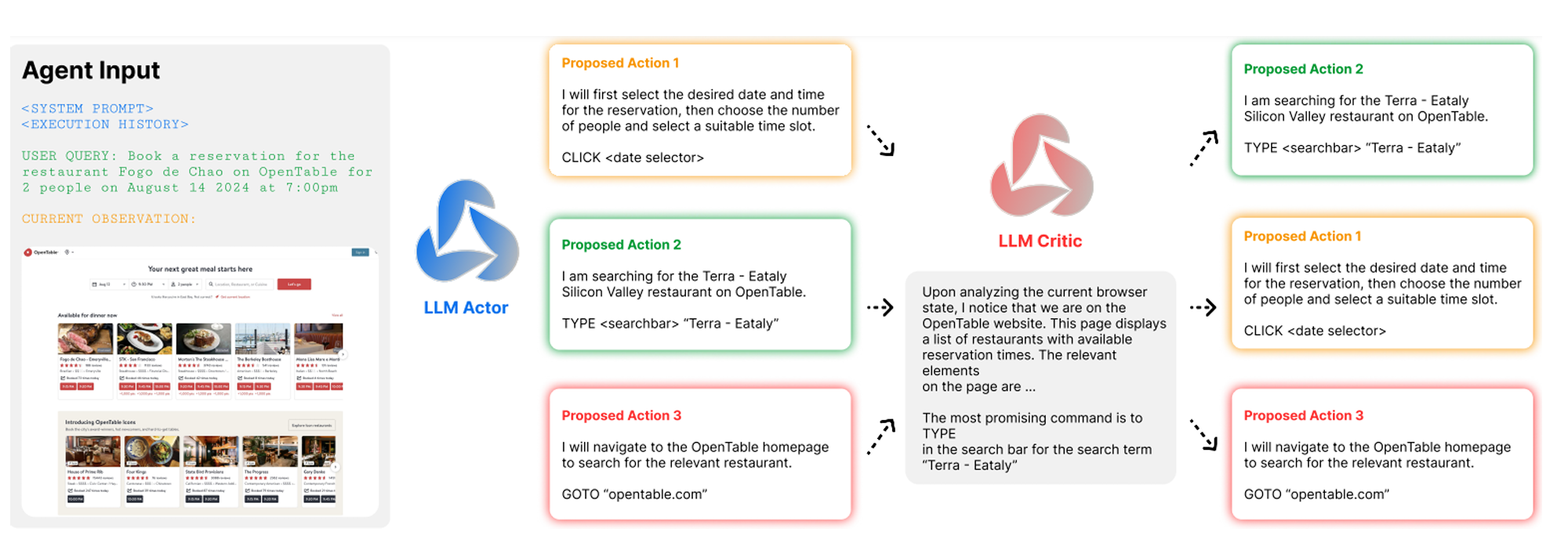
【AI生成】图4解释
这张图是理解Agent Q框架中AI过程监督(AI Process Supervision)这一核心创新的关键。它展示了在MCTS的“选择”(Selection)阶段,如何利用一个“批评模型”(LLM Critic)来解决网页环境中的稀疏奖励问题。
整体流程概览
图4描绘了一个循环过程:
- 策略(Actor)提出动作:在当前网页状态(Agent Input)下,主模型(LLM Actor)生成多个可能的下一步动作。
- 批评模型(Critic)进行排序:另一个独立的模型(LLM Critic)对这些动作进行评估和排序,判断哪个动作更有可能成功。
- 利用排序结果:这个排序结果被用来指导MCTS的后续步骤,既在探索时(inference-time search)帮助选择更优路径,也在训练时(policy training)用于构建数据。
详细分解
- 左侧:Agent Input (智能体输入)
- 这是与图2相同的输入格式,包含了用户查询(
Book a reservation for the restaurant Fogo de Chao...)和当前观察到的OpenTable主页截图。 - 当前状态是:用户需要在OpenTable上找到特定餐厅,但尚未输入任何信息。
- 中间:LLM Actor (主模型/策略)
- 这是执行任务的“大脑”,即经过初步训练的LLM。
- 它根据输入,生成了三个可能的下一步动作(
Proposed Action 1,Proposed Action 2,Proposed Action 3):
- Action 1 (橙色):点击日期选择器。这是一个合理的动作,但不够具体。
- Action 2 (绿色):在搜索栏中输入“Terra - Eataly”。这是一个非常直接且高效的行动,能快速定位目标餐厅。
- Action 3 (红色):导航回OpenTable首页。这是一个错误的动作,因为当前已经在主页上,这会浪费步骤。
- 右侧:LLM Critic (批评模型)
- 这是“自我监督”的关键。它是一个与主模型(Actor)完全相同的基础LLM模型(例如,都是LLaMA-3 70B)。它不负责执行任务,只负责“思考”和“评判”。
- 它接收主模型提出的三个动作,并基于其自身的“直觉”对它们进行分析和排序。
- 批评模型的思考(灰色框):
“在分析当前浏览器状态后,我注意到我们正在OpenTable网站上。此页面显示了带有可用预订时间的餐厅列表。页面上的相关元素是……”
“最有可能成功的命令是在搜索栏中输入搜索词‘Terra - Eataly’。”
- 这个思考过程表明,批评模型能够理解当前环境(在主页上,有搜索栏),并能评估不同动作的合理性。它认为Action 2 是最佳选择。
- 结果:动作排序与反馈
- 批评模型的判断结果体现在右侧的重新排列上:
- Action 2 (绿色) 被排在第一位,因为它被判定为“最有可能成功的命令”。
- Action 1 (橙色) 被排在第二位。
- Action 3 (红色) 被排在第三位,因为它是一个无效或低效的动作。
- 这个排序就是所谓的“AI过程监督”(AI Process Feedback)。它为每个动作提供了一个中间奖励(intermediate reward),即使该动作最终没有导致任务成功。
核心意义与应用
- 解决稀疏奖励问题:在真实的网页环境中,只有在任务完成时才能获得“成功/失败”的最终奖励。如果一个动作(如Action 3)在早期就犯了错误,整个轨迹都会失败,模型无法知道是哪个具体的动作导致了失败。AI过程监督通过批评模型提供的即时反馈,解决了这个问题。它告诉MCTS:“虽然你没成功,但你的Action 2是正确的,而Action 3是错的。”
- 指导MCTS搜索:在MCTS的“选择”阶段,这个排序可以作为启发式信息,优先探索那些被批评模型评为“好”的动作路径,从而加速搜索过程。
- 构建训练数据:在训练阶段,这个排序结果被用来计算一个加权的Q值(见公式(10)),以构建用于DPO训练的“偏好对”。例如,在某个节点上,如果Action 2被排在第一,而Action 3被排在最后,那么这对动作就可以构成一个“优选” vs “劣选”的对比对,用于训练主模型。
总而言之,图4生动地展示了Agent Q如何利用一个相同的、强大的LLM作为“自我批评者”,来为复杂的网页交互任务提供细粒度的、实时的反馈,从而极大地提升了学习效率和最终性能。
扩展
- 动作生成:使用基础LLM策略(
πθ)在当前节点(网页状态)上采样K个可能的动作(如CLICK[ELEMENT ID],TYPE[CONTENT])。 - 执行:选择一个动作在浏览器环境中执行,进入下一个网页状态,创建新的子节点。
模拟
- 过程:从新创建的叶节点开始,使用当前的策略模型
πθ进行rollout,直到任务成功或失败。 - 目的:快速评估该分支的最终奖励R(成功时R=1,失败时R=0)。
回溯
- 更新:将模拟得到的最终奖励(R=1/0)从叶节点反向传播到根节点。
- 更新内容:更新路径上每个 (state, action) 对的访问次数
和MCTS的平均
:



DPO(Direct Preference Optimization)
为什么选用DPO
- 强化微调 (Reinforced Fine-Tuning, RFT)简单但性能通常低于标准RL。
- DPO是经典RLHF优化流程的一种离线RL替代方案,无需在线采样。
DPO工作原理
- 作用:训练时,LLM会通过微调(fine-tuning)的方式,调整其所有参数
θ,朝着使损失函数 DPO loss 最小化的方向进行优化。 - 范围:DPO loss 是对整个
的 log-likelihood(plan/thought/env/expl 部分全部拼在一起)做梯度更新的,因此虽然MCTS的数据针对env action,但DPO最终可以调整LLM的plan、thought和explanation。
- 数据来源:使用MCTS生成的轨迹,构造偏好对(preferred vs. dispreferred)。
训练时优化的不是单独的Env Action
被训练的策略模型(policy)即 LLM with parameters,输出是一个完整的 step action 
- 第一步:
- 之后步骤:


在优化时,DPO loss 是对整个
公式 (1) 说明
- 公式 (1) 是论文中用于定义复合动作(composite action)的联合似然性(joint likelihood)的核心,解释了模型
在给定历史
的情况下,生成一个完整动作
的概率是如何计算的。
- 该公式的结果
将在后续的DPO优化中使用。




【相关原文】3.1. Agent Formulation, page 6
We denote the step action 

for the initial action and

for subsequent actions, unlike some prior works Zhai et al. (2024), which down-weight the reasoning likelihood.
对于第一步(t=1),模型需要同时生成四个组件。公式 (1) 将这四个部分的似然性相加:

t=1时似然公式的参数说明
:

- 生成计划(Plan)的概率。
- 在第一步,模型根据用户指令和初始网页状态
,生成一个高层次的、分步骤的任务执行方案。

:

- 生成推理(Thought)的概率。
- 模型在知道计划后,生成下一步的具体思考过程,解释为什么选择某个动作。
:

- 生成环境动作(Environment Action)的概率。
- 这是真正与浏览器交互的指令(如
"CLICK[123]")。它的生成依赖于当前的状态和计划
。


:

- 生成解释(Explanation)的概率。
- 模型在生成了环境动作后,会提供一个解释,说明这个动作的意图是什么。
这里使用的是对数似然性 (log π),而不是直接的似然性 (π)。这是为了数值稳定性和方便数学运算(将乘法转换为加法)。
- 后续动作的联合似然 (Subsequent Actions)
对于第 t 步(t > 1),模型不再需要生成“计划”,因为它已经有一个初步的计划。因此,后续动作的联合似然性只包含三个部分:

t>1时似然公式的参数说明
:根据当前的历史
(包括之前的动作和当前的网页状态),生成当前步骤的thought。
:根据当前历史
,生成env action。
$: 根据当前历史
和推理
,生成explanation。







从env action的偏好传导到其他部分
MCTS的偏好对针对于env action候选;在此基础上,DPO从env action偏好传导到其他部分。
- 数据构造
- MCTS rollout 给出的是“(history
) 的偏好”。
- 但训练时我们不单独输入 env action,而是把 完整的 composite action(包含当时生成的 plan/thought/env/expl)当作候选轨迹。
- MCTS rollout 给出的是“(history
- DPO Loss 计算

- 单步DPO:

单步 DPO loss 参数说明
:训练时要最小化这个损失函数。
:被训练的策略模型(policy),即 LLM with parameters。


:被训练的参数,它输出给定历史
下,生成某个 composite action
的概率。



:参考模型(reference policy)。通常就是初始的 SFT 模型,用来稳定训练,防止策略无限制偏离原始分布。
:数据集,包含很多个偏好对 (preference pairs)。每个样本形如
。



:较优的动作(来自 MCTS Q 值高的 env action 轨迹)。
:较劣的动作。


:对数据集里的所有偏好对取平均(数学上的“期望”)。所以最终 loss 是在整个训练集上的平均损失。
:缩放系数,控制 policy 与参考模型之间的偏差有多敏感。


:当前模型在历史
下输出优动作
:同理,是劣动作的概率。
:这里的
是 sigmoid 函数。log-sigmoid 的形式和对比学习类似,确保:





- 如果优动作相对参考模型的概率比劣动作更大 → loss 变小;
- 如果模型错误地更偏向劣动作 → loss 变大,强迫模型纠正。
- 轨迹级DPO:
- 虽然偏好标签来自 env action,但训练信号被应用到了 plan/thought/expl + env 整体序列的 likelihood。
- 采用无策略重放缓冲区,缓解计算资源,避免独立参考模型。

- 条件传导
- 因为 env action 的选择是依赖于 plan/thought/expl 的上下文(模型是自回归的),如果 thought/expl 给出的“上下文”更有助于生成更优的 env action,它们的概率分布就会被调整。
- 换句话说,DPO 在优化 env action 的同时,顺带推动模型去产生那些“能更好引导 env action” 的 plan/thought/expl。
打个比方
假设有两个 rollout:
- 坏轨迹:
- thought: “我应该立即点确认”
- env action:
CLICK [wrong button]
- 好轨迹:
- thought: “先检查餐厅是否有空位”
- env action:
CLICK [availability button]
MCTS 会给 第二条 env action 更高的 Q 值。
→ DPO 偏好对就标记第二条轨迹更优。
→ 优化时,整个序列 (thought + env + explanation) 的 log-likelihood 都会被提升。
→ 于是模型学到“这种 thought 更可能导致好 env action”,以后也更倾向生成这种思路。
通过强化学习提升零样本性能
- 目标:利用MCTS生成的轨迹数据,通过DPO离线训练,提升模型的内在能力。
- 理论基础:Theorem 1 表明,若偏好对(preference pairs)基于最优Q值生成,则DPO优化等价于最优RL策略。
- 偏好对构造:
- 在MCTS树同一父节点(状态)的每个节点,比较不同子节点(动作)的Q值。
- 如果两个动作的Q值差异超过阈值
,则构造一个偏好对。
- 最终Q值:采用加权平均
:通过MCTS回溯得到的。
- 偏好对
:当处于
状态时,应该选择
,而不是
。
- 结果:训练后的模型(Agent Q)即使在不使用MCTS的情况下(零样本),其性能也远超基线。







图表说明
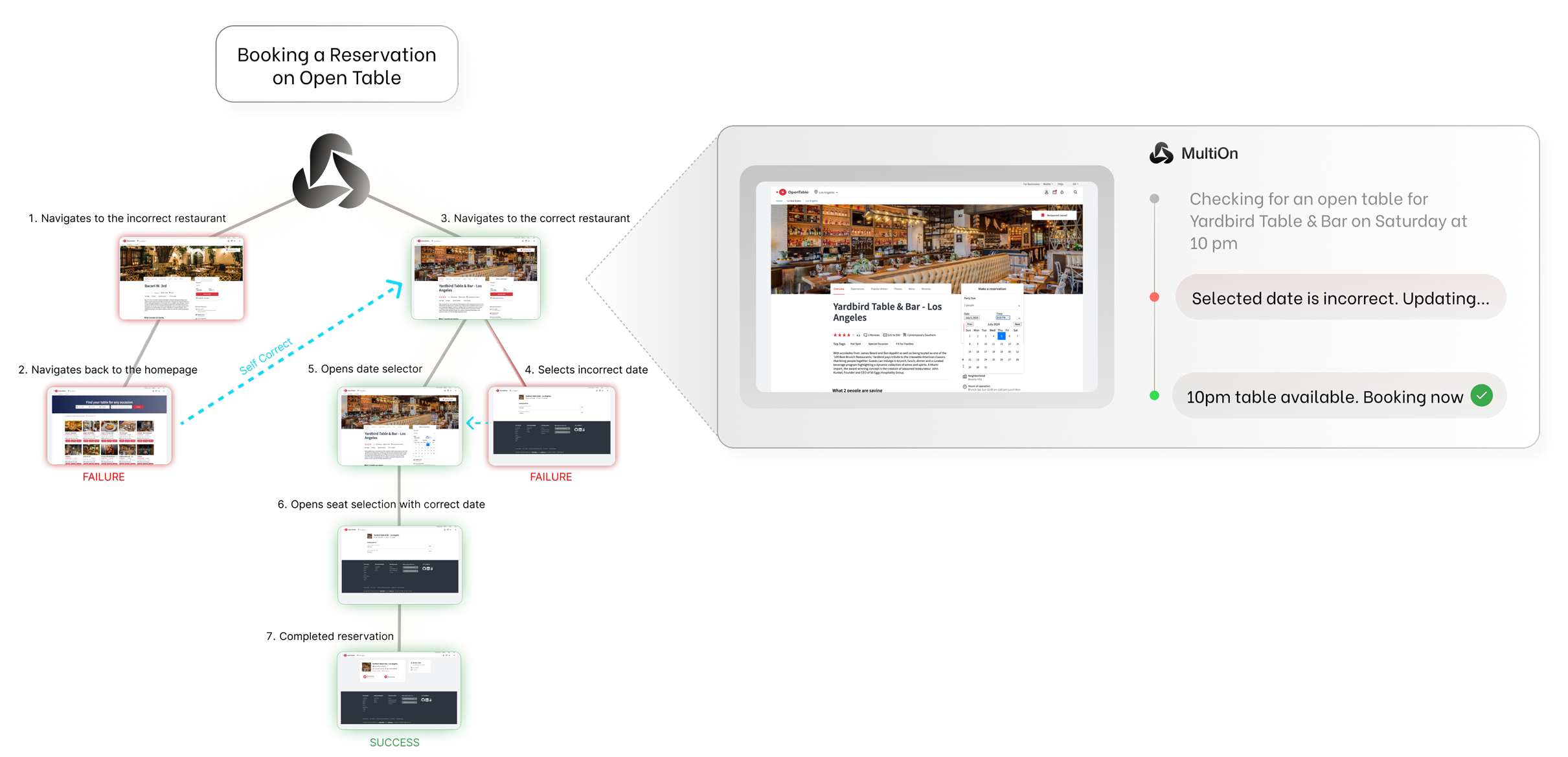
【AI生成】图1解释
这张图是理解Agent Q框架核心思想的“全景图”。它清晰地展示了训练阶段(Training Phase)的整个流程,特别是如何将MCTS和DPO结合起来。
整体流程概览
整个过程是一个循环:
- 起点:从一个具体的任务开始(如“在OpenTable上预订餐厅”)。
- MCTS探索:使用MCTS算法在可能的行动路径上进行探索,生成大量的成功和失败的交互轨迹。
- 数据构建:利用MCTS探索过程中产生的信息(Q值、AI反馈),构建一个“偏好对”数据集。
- DPO训练:使用这个偏好对数据集,通过DPO算法对基础LLM模型进行微调,使其学习到更优的决策策略。
- 迭代:用新训练好的模型再次进行MCTS探索,如此循环往复,不断迭代优化模型。
详细分解
- 左侧:MCTS 搜索树 (The Search Tree)
- 根节点 (Root Node):代表初始状态,即用户的任务指令(“Booking a Reservation on Open Table”)。
- 树枝 (Branches):代表了在执行任务时可能采取的不同动作序列。
- 节点 (Nodes):代表了网页上的一个具体状态或决策点。例如,“导航到错误的餐厅”、“选择错误的日期”等。
- 颜色编码 (Color Coding):
- 深绿色 (Darker Green):表示该路径(或该节点)的累积奖励高,意味着这条路径更有可能通向成功。
- 深红色 (Darker Red):表示该路径(或该节点)的累积奖励低,意味着这条路径很可能导致失败。
- 这个颜色编码直观地展示了MCTS如何通过反复模拟和回溯,为每条路径“打分”,从而引导搜索向更成功的方向发展。
- 路径示例:
- 成功路径 (SUCCESS):
1 -> 3 -> 5 -> 6 -> 7。这条路径经过一系列正确的操作,最终完成了预订,因此被标记为“SUCCESS”。 - 失败路径 (FAILURE):
1 -> 2和3 -> 4。这些路径因为选择了错误的餐厅或日期而失败,因此被标记为“FAILURE”。
- 右侧:AI过程监督 (AI Process Supervision)
- 这个部分展示了MCTS是如何在探索过程中获得“中间奖励”的。
- 背景:在真实的网页环境中,只有在任务完成时才会得到最终的“成功/失败”奖励(稀疏奖励)。这使得模型很难判断中间步骤的好坏(信用分配问题)。
- 解决方案 - AI反馈:作者引入了一个“反馈语言模型”(Feedback Language Model),它也是一个LLM(可能是和主模型相同的模型)。
- 工作方式:
- 当MCTS到达一个决策点(比如要点击哪个按钮)时,它会从主模型那里采样出多个可能的动作(K个)。
- 然后,反馈语言模型会被询问:“在当前情况下,你认为这些动作哪个更有助于完成任务?”
- 反馈模型会根据其自身的“直觉”对这些动作进行排序和打分。
- 目的:这个由AI生成的“过程监督”分数(Process Feedback Score)作为一个中间奖励,被用来指导MCTS的搜索。它让MCTS能“提前知道”某个动作是否看起来“正确”,从而优先探索那些被AI认为是好主意的路径。
- 连接与整合 (Connecting the Dots)
- 图中的箭头表明了MCTS搜索的结果(即所有探索过的路径及其Q值、AI反馈分数)被用来构建一个“偏好对”数据集。
- 具体来说,对于搜索树中的每一个节点,如果两个子节点的Q值差异足够大(超过阈值
θthreshold),就会形成一个“优选”(preferred)和“劣选”(dispreferred)的对比对。 - 这个对比对的数据集就是DPO算法的输入。DPO会利用这些数据来训练主模型,让模型学会在相同的历史下,生成“优选”响应的概率远高于“劣选”响应的概率。
总结
图1的核心意义在于,它展示了一个闭环的、自我强化的学习系统:
- MCTS 是一个强大的“探索者”和“数据生成器”,它通过结合AI过程监督来解决稀疏奖励的问题,生成高质量的训练数据。
- DPO 是一个高效的“学习者”,它利用MCTS生成的“谁更好”的偏好数据,直接优化模型的参数。
- 两者结合,使得模型能够从自己的探索经验中持续学习,不断提升在复杂、多步骤任务中的决策能力。

【AI生成】算法1解释
算法1:MCTS引导的直接偏好优化(MCTS Guided Direct Preference Optimization)
输入:πθ0:初始LLM策略,DT:代理必须在环境中完成的任务数据集,N:迭代次数,B:每次迭代的样本数,T:MCTS树深度,ℬ:重放缓冲区(replay buffer),θthreshold:公式(10)中的值阈值,K:为MCTS采样的动作数量
输出:πθN,训练好的LLM策略
for i = 1 to N do
πref ← πθi, πθi ← πθi−1
从 DT 中采样一批大小为 B 的任务
for each task in batch do
初始化根节点 h0
for t = 1 to T do
选择(Selection):使用树策略(UCB1;7)从根节点遍历到叶节点
轨迹回放(Trajectory Rollout):从选定节点的轨迹开始,使用 πθi 回放轨迹,直到达到终止状态
回溯(Backpropagation):自底向上地反向传播价值估计(8)
end for
从回放中收集轨迹并存储在重放缓冲区 ℬ 中
end for
构造偏好对 DP = {(ht, awt, alt)}T−1 t=1,其中 ht ∼ DP。对于每个步骤 t 的节点,比较每对子节点,并构造生成的动作对 (aw, al),如果采取该动作的价值差异 |Q(ht, aw) - Q(ht, al)| > θthreshold,其中 Q(ht, aw) 和 Q(ht, al) 是通过公式(10)计算的。
使用公式(5)中的DPO目标函数,结合 DP 和 πref,优化LLM策略 πθi
end for
这个算法是Agent Q框架的核心,它将MCTS搜索和DPO训练紧密地结合在一起,形成一个迭代优化的闭环。它的主要目标是利用MCTS探索产生的“经验”来不断改进LLM策略。
整体流程概览
整个过程是一个循环,共进行 N 次迭代:
- 准备阶段:
- 在每次迭代
i开始时,将上一次迭代训练好的模型πθi−1设置为当前的参考模型πref。 - 将当前要训练的模型初始化为
πθi,它在本次迭代中会根据新数据被更新。
- 数据收集阶段(MCTS):
- 从任务数据集
DT中随机抽取一批任务(B个)。 - 对于每一个任务,执行一个完整的MCTS搜索过程(见第5.1节):
- 选择(Selection):使用UCB1公式从根节点(任务初始状态)向下遍历,直到找到一个叶节点(未探索的决策点)。
- 轨迹回放(Trajectory Rollout):从这个叶节点开始,使用当前的LLM策略
πθi进行模拟(rollout),直到任务成功或失败,得到一个完整的交互轨迹。 - 回溯(Backpropagation):将这个轨迹的最终奖励(R=1/0)从叶节点反向传播到根节点,更新路径上所有
(状态, 动作)对的访问次数N(ht, ait)和平均Q值Q(ht, ait)。
- 所有这些由MCTS生成的轨迹都被收集起来,并存入一个重放缓冲区
ℬ。
- 数据处理与训练阶段(DPO):
- 构建偏好对:从重放缓冲区
ℬ中提取数据,为DPO训练构建“对比对”。具体来说,对于MCTS树中每个时间步t的节点ht,会比较其所有子节点(即不同的可能动作)。如果两个动作aw和al的Q值差异超过预设的阈值θthreshold,就认为aw是更优的,从而构成一个“优选” vs “劣选”的偏好对(ht, aw, al)。 - 模型训练:使用这些构建好的偏好对数据集
DP和参考模型πref,通过DPO的损失函数(公式5)来优化当前的LLM策略πθi。这一步会更新模型的内部参数θ。
关键细节解析
- 重放缓冲区(Replay Buffer
ℬ):这是一个非常重要的组件。它允许算法在一次MCTS搜索中收集大量轨迹,并在后续的多个DPO训练迭代中重复使用这些数据,从而提高了数据利用效率,避免了每次都重新进行昂贵的MCTS搜索。 πref的作用:πref是一个固定的参考模型,在本次迭代中不会被改变。它在DPO的损失函数中作为“基准”,用来衡量新策略πθi相对于旧策略的改进程度,防止模型在训练过程中偏离太远(out-of-distribution drift)。θthreshold的作用:这个阈值用于过滤掉那些Q值差异很小、难以判断优劣的行动对。只保留那些差距明显的对比对,可以提高训练信号的质量,使DPO学习到更清晰的偏好。- 迭代优化:这是算法的精髓。经过一轮DPO训练后,模型
πθi会变得更强。在下一轮迭代中,这个更强的模型πθi又会被用作新的πθi−1来进行MCTS搜索。这意味着新的MCTS搜索会基于一个更聪明的“大脑”进行,从而能探索出更优的路径,产生更高质量的训练数据,进而让模型变得更强大。这个正向循环是Agent Q性能提升的关键。
总结
算法1完美地诠释了论文的核心思想:“用搜索来指导学习,用学习来增强搜索”。MCTS作为一个强大的探索者,负责生成高质量的数据(轨迹和偏好对);DPO作为一个高效的学习者,负责利用这些数据来优化模型。两者通过迭代的方式相互促进,共同推动LLM策略的持续进化。