实验(推理阶段)
虚拟环境
WebShop介绍(摘自WebShop论文)
- 环境:一个模拟的电子商务平台,用于基准测试。
- 任务场景:搜索页(search)、结果页(results)、商品详情页(item)、进一步的详情页(item-detail)等。
- 是否多跳:
- 涉及多页面导航:Agent 需从搜索页面开始,通过点击搜索结果、进入商品页面,进一步定制选项后进行购买,跨越多个页面完成任务。但都在同一模拟网站中进行。
- WebShop 的任务虽多页面跳转,但限定在同一站点/模拟环境中。
- 任务评估:
- 通过解析HTML内容来获取agent执行操作后的结果数据。
- 由类型、属性、选项、价格匹配组成。
- r=1时任务成功。

实验结果
- 基础模型(xLAM-v0.1-r)零样本成功率:28.6%。
- 基础模型+RFT(仅使用成功轨迹):提升至31.3%。
- 基础模型+DPO(成功 vs 失败轨迹):提升至40.6%,说明DPO优于RFT。
- 基础模型+MCTS(推理阶段启动MCTS):提升至48.4%,说明推理时使用MCTS有巨大性能提升。
- Agent Q(训练阶段包含MCTS+AI监督+DPO,零样本):41.5%。
- Agent Q+MCTS(推理阶段启用MCTS):提升至50.5%,说明推理时使用MCTS有巨大性能提升。
图表说明
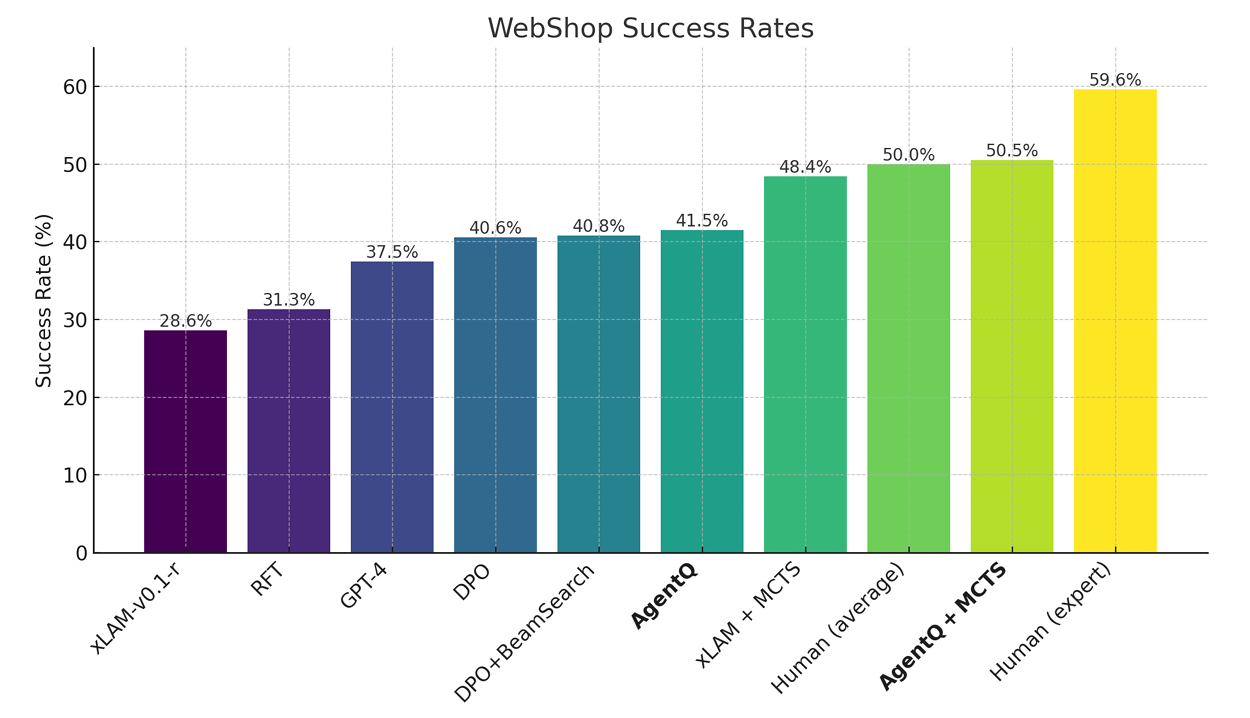
【AI生成】图3解释
这张图是衡量Agent Q框架性能的核心图表之一。它清晰地展示了在模拟环境(WebShop) 中,不同方法的性能对比,突出了Agent Q+MCTS组合的巨大优势。
整体解读
这是一个条形图,横轴是不同的方法或模型,纵轴是它们在WebShop基准测试上的成功率为百分比。这个成功率达到50% 是一个关键的参考点,因为它代表了“平均人类”的表现水平。
各条形柱详解
xLAM-v0.1-r(深紫色):
- 含义:这是所有其他方法的基线模型。它是经过监督微调(SFT)的LLM,但没有经过额外的强化学习或搜索优化。
- 成绩:28.6%。这表明即使是强大的预训练模型,在没有进一步优化的情况下,其零样本能力也有限。
RFT(深紫色):
- 含义:Reinforced Fine-Tuning(强化微调)。这是一种基于结果监督(outcome-based supervision)的方法,它使用成功轨迹来训练模型。
- 成绩:31.3%。相比基线模型有小幅提升(+2.7%),但效果有限。
GPT-4(深蓝色):
- 含义:作为另一个强大的基线模型进行比较。
- 成绩:37.5%。虽然比xLAM-v0.1-r强,但仍然远低于人类水平。
DPO(深蓝色):
- 含义:Direct Preference Optimization(直接偏好优化)。这是一种更先进的RLHF方法,利用成功和失败的轨迹来构建偏好对,从而训练模型。
- 成绩:40.6%。比RFT和GPT-4都好,证明了DPO的有效性,但仍落后于人类。
DPO+BeamSearch(青色):
- 含义:在DPO训练的基础上,结合了束搜索(Beam Search)这种推理时的规划技术。
- 成绩:41.5%。与纯DPO相比,提升非常小,说明简单的规划技术在这个任务上效果有限。
AgentQ(绿色):
- 含义:这是指经过Agent Q框架(即MCTS+AI过程监督+DPO)训练后的模型,但在评估时没有启用MCTS搜索(即零样本模式)。
- 成绩:48.4%。这个成绩非常关键,它表明仅仅通过训练(DPO),模型的能力就得到了巨大提升,已经接近人类平均水平。
xLAM + MCTS(浅绿色):
- 含义:将未训练的基线模型(xLAM-v0.1-r)与推理时的MCTS搜索相结合。
- 成绩:50.0%。这个结果非常重要,它证明了MCTS搜索本身就能带来巨大的性能提升,使一个未经强化训练的模型达到人类平均水平。
Human (average)(浅绿色):
- 含义:平均人类的表现。
- 成绩:50.0%。作为基准线。
AgentQ + MCTS(亮黄色):
- 含义:这是最终的、最强的组合。它将经过训练的Agent Q模型与推理时的MCTS搜索结合起来。
- 成绩:50.5%。这是所有方法中最高的,超过了平均人类的表现。
Human (expert)(亮黄色):
- 含义:专家人类的表现。
- 成绩:59.6%。这是人类能达到的最高水平,为未来的研究设定了一个更高的目标。
核心结论
- 训练很重要:
AgentQ(48.4%) vsxLAM-v0.1-r(28.6%)的对比,证明了通过MCTS生成数据并用DPO训练模型,能极大地提升模型的内在能力。 - 搜索很重要:
xLAM + MCTS(50.0%) vsxLAM-v0.1-r(28.6%)的对比,证明了在推理时使用MCTS搜索能有效弥补模型推理能力的不足。 - 两者结合是关键:
AgentQ + MCTS(50.5%)的成绩,是训练(提升模型能力)和搜索(在执行时进行规划)协同作用的结果。它不仅超越了基线模型,还超越了平均人类表现,展现了该框架的强大潜力。
总而言之,图3有力地证明了Agent Q框架在模拟环境中的有效性,特别是当将训练和推理时的搜索能力结合起来时,能够产生超越人类平均水平的性能。
真实世界
OpenTable介绍
- 环境:一个真实世界的餐厅预订网站。
- 挑战:真实、动态、步骤多(平均13.9步,远超WebShop的6.8步)。
- 成功判定:使用 GPT-4-V 作为评估器,基于最终状态截图和执行历史,根据四项标准(时间、人数、信息、点击按钮)给出二元(0/1)成功信号。
- 成功判定:使用GPT-4-V 作为评估器,根据最终状态截图和历史给出二元(0/1)成功信号。
- 动作空间:CLICK, GOTO, TYPE, SUBMIT, CLEAR, SCROLL, ASK USER等。
实验结果
- 基础模型(LLaMA-3 70B Instruct)零样本成功率:18.6%。
- RFT:提升至67.2%。
- DPO:提升至71.8%,说明DPO优于RFT。
- RFT+MCTS(推理):提升至84.3%,说明推理时使用MCTS有巨大性能提升。
- Agent Q:提升至81.7%。
- Agent Q+MCTS(推理):提升至95.4%,说明推理时使用MCTS有巨大性能提升。
图表说明
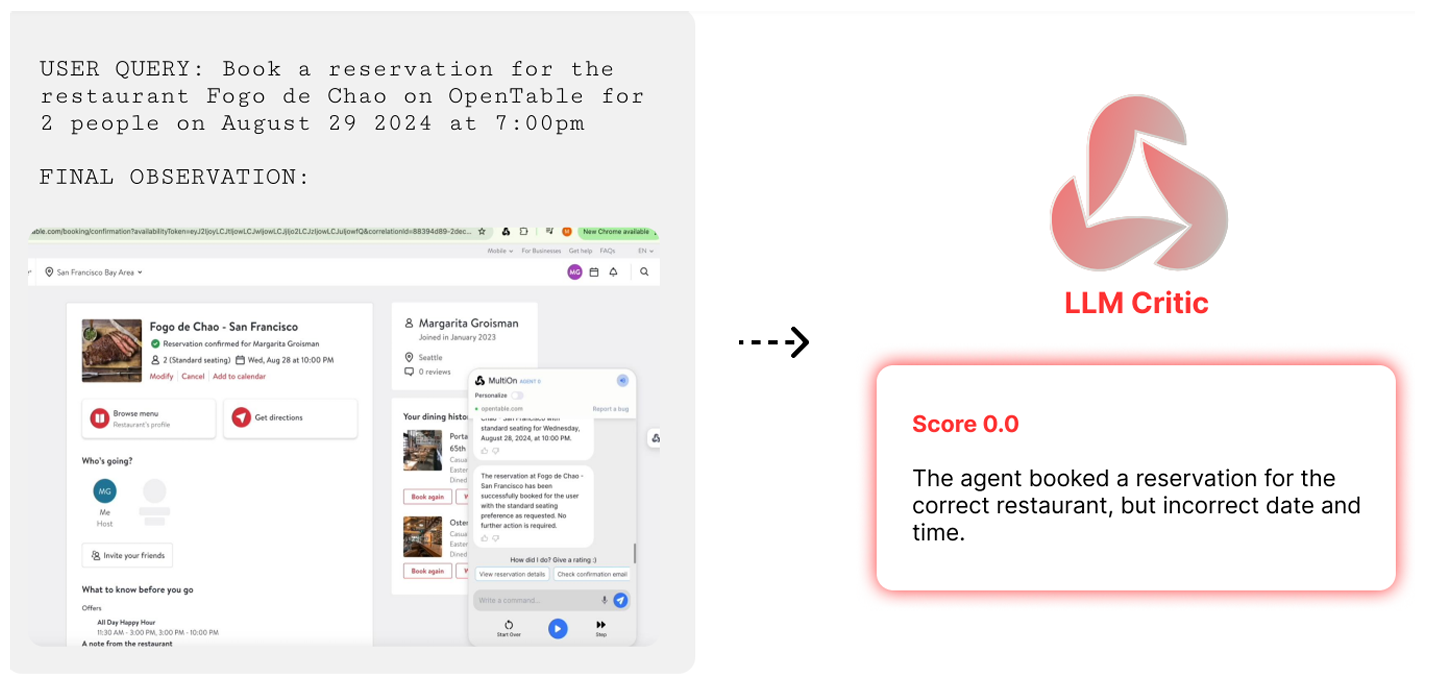
【AI生成】图5解释
这张图是理解Agent Q框架如何进行最终任务评估(Final Task Evaluation)的关键。它展示了在训练阶段(Training Phase),特别是当使用MCTS探索生成数据时,如何为一个完整的交互序列(trajectory)打上“成功”或“失败”的标签。
整体流程概览
整个过程是:
- 执行轨迹:智能体从用户查询开始,经过一系列思考、规划和行动,最终到达一个网页状态。
- 调用评估器:在轨迹的终点,系统会自动调用一个外部的、强大的语言模型(GPT-4-V)来评判这个轨迹的最终结果。
- 获取反馈:GPT-4-V根据提供的信息,给出一个二元的成功分数(0或1)和一段文字说明。
详细分解
- 左侧:最终观察 (FINAL OBSERVATION)
- 这是智能体执行完所有操作后,浏览器显示的最终页面截图。
- 在图中,我们可以看到:
- 智能体成功预订了餐厅 Fogo de Chao。
- 预订的日期是 8月28日(Wed, Aug 28, 2024),但用户请求的是 8月29日。
- 预订的时间是 晚上7点,这与用户请求一致。
- 这个观察是真实的、视觉化的,它包含了所有最终的、可验证的信息。
- 中间:LLM Critic (批评模型)
- 这里的“LLM Critic”实际上指的是GPT-4-V,它是论文中用于评估任务完成情况的工具。
- 它接收两个关键输入:
- 最终观察:即上面的截图。
- 浓缩的执行历史:虽然图中没有直接展示,但论文描述了这一点。这个历史记录了智能体在整个任务中采取的所有关键步骤(如点击了哪个按钮、输入了什么内容等),以便评估器了解整个过程。
- 右侧:评估结果 (Score & Feedback)
- Score: 0.0:这是最关键的输出。它是一个二元(binary) 的成功指标。
0.0表示失败,1.0表示成功。 - 反馈文本:“The agent booked a reservation for the correct restaurant, but incorrect date and time.” (智能体为正确的餐厅预订了座位,但日期和时间不正确。)
- 核心逻辑:尽管智能体完成了大部分工作(找到了正确的餐厅并提交了预订),但由于日期错误,任务被视为失败。这体现了评估标准的严格性——必须满足所有预设条件才算成功。
为什么需要GPT-4-V?
- 解决真实环境的挑战:在OpenTable这样的真实网站上,无法通过程序化的方式(programatically)读取后台数据库来验证预订是否真正成功。例如,系统无法直接知道预订的日期是否正确。
- 视觉理解能力:GPT-4-V作为一个多模态大模型,具备强大的视觉理解能力。它能够“看懂”截图中的所有元素(如文本、按钮、图标),并准确地提取出关键信息(如餐厅名称、日期、时间)。
- 综合判断:它不仅能识别信息,还能将这些信息与用户查询进行对比,并做出最终的判断。这比简单的文本匹配要复杂得多。
总结
图5的核心意义在于,它展示了Agent Q框架如何利用一个强大的外部模型(GPT-4-V)作为“裁判” 来解决真实世界任务评估的难题。这种基于视觉的、综合性的评估方式,确保了训练数据的质量,使得DPO算法能够学习到真正有用的策略,而不仅仅是学会如何在模拟环境中“作弊”。
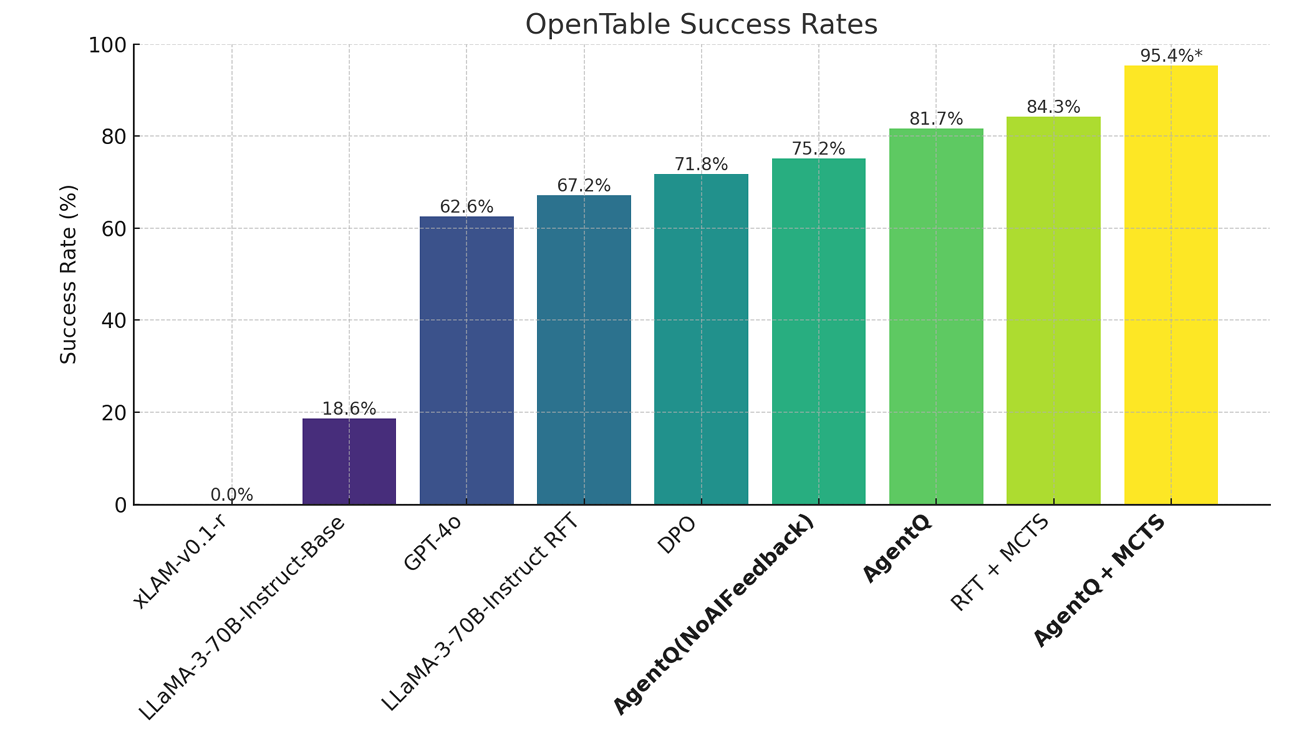
【AI生成】图6解释
这张图是论文最核心、最令人印象深刻的实验结果之一。它展示了Agent Q框架在真实世界网站(OpenTable) 上的巨大威力,特别是当将训练后的模型与推理时的MCTS搜索相结合时,其性能达到了惊人的高度。
整体解读
这是一个条形图,横轴是不同的方法或模型,纵轴是它们在OpenTable任务上的成功率为百分比。这个图表清晰地呈现了一个“阶梯式”的性能提升过程。
各条形柱详解
xLAM-v0.1-r(深紫色):
- 含义:这是基线模型,一个经过监督微调的LLM。
- 成绩:0.0%。这表明该模型在没有进一步优化的情况下,完全无法完成预订任务。
LLaMA-3-70B-Instruct Base(深紫色):
- 含义:这是另一个更强的基线模型,即LLaMA-3 70B Instruct模型,但未经过任何特定训练。
- 成绩:18.6%。这代表了该强大模型的零样本(zero-shot)能力。虽然比第一个基线好得多,但仍然远低于人类水平。
GPT-4o(深蓝色):
- 含义:作为另一个强大的基线模型进行比较。
- 成绩:62.6%。这显示了即使是顶级的商业模型,在这种复杂的、多步骤的真实世界任务上,其零样本表现也有限。
LLaMA-3-70B-Instruct RFT(深蓝色):
- 含义:在LLaMA-3 70B Instruct模型上应用了强化微调(Reinforced Fine-Tuning, RFT)。
- 成绩:67.2%。相比基线模型有显著提升,证明了RFT的有效性。
DPO(青色):
- 含义:在LLaMA-3 70B Instruct模型上应用了直接偏好优化(Direct Preference Optimization, DPO)。
- 成绩:71.8%。比RFT稍好,但效果提升有限。
AgentQ (No AI Feedback)(青色):
- 含义:这是Agent Q框架的一个变体,它使用了MCTS+DPO,但去除了AI过程监督(即批评模型)。
- 成绩:75.2%。这个结果非常重要,它证明了即使没有AI反馈,仅通过MCTS探索生成数据并用DPO训练,也能带来显著的性能提升。
AgentQ(绿色):
- 含义:这是完整的Agent Q框架,包含了MCTS探索、AI过程监督和DPO训练。
- 成绩:81.7%。这是零样本(zero-shot)性能,即模型在不使用MCTS搜索的情况下,仅凭自身学习到的能力执行任务。这个成绩已经是一个巨大的飞跃,是基线模型的4倍多。
RFT + MCTS(浅绿色):
- 含义:将RFT训练的模型与推理时的MCTS搜索相结合。
- 成绩:84.3%。这证明了MCTS搜索本身就能极大地提升模型的决策质量,使一个未经充分训练的模型达到很高的性能。
AgentQ + MCTS(亮黄色):
- 含义:这是最终的、最强的组合。它将经过完整训练的Agent Q模型与推理时的MCTS搜索结合起来。
- 成绩:95.4%。这是所有方法中最高的,标志着Agent Q框架的巅峰性能。这个成绩不仅远超所有基线模型,甚至可能接近或超过了人类专家的水平(文中提到专家人类为59.6%,但这里指的可能是平均人类)。
核心结论
- 训练至关重要:从
Base(18.6%) 到AgentQ(81.7%) 的巨大差距,证明了通过MCTS+DPO+AI反馈进行训练,能将一个强大的基础模型的潜力发挥到极致。 - 搜索是关键:从
AgentQ(81.7%) 到AgentQ + MCTS(95.4%) 的提升,证明了在推理时启用MCTS搜索,能让模型进行更高级的规划和探索,从而获得“超人”般的性能。 - 两者结合是王道:
AgentQ + MCTS是一个完美的组合,它结合了强大的内在能力(训练)和卓越的外部工具(搜索),共同创造了前所未有的高成功率。
总而言之,图6有力地证明了Agent Q框架在解决复杂、真实的Web代理任务方面的巨大潜力,尤其是在将训练和推理时的搜索能力相结合时,能够实现质的飞跃。