https://www.arxiv.org/abs/2601.12538
推理是推断、问题解决和决策的基础认知过程。尽管LLMs在封闭世界环境中展现出强大的推理能力,但在开放式和动态环境中却面临挑战。智能体推理(Agentic reasoning)标志着一个范式转变,它将LLMs重构为通过持续交互进行规划、行动和学习的自主智能体。 在本综述中,我们沿着三个互补的维度来组织智能体推理。首先,我们通过三个层面来刻画环境动态:基础智能体推理,它在稳定环境中建立核心的单智能体能力,包括规划、工具使用和搜索;自进化智能体推理,它研究智能体如何通过反馈、记忆和适应来完善这些能力;以及集体多智能体推理,它将智能扩展到涉及协调、知识共享和共同目标的协作环境中。在这些层面之上,我们区分了上下文推理(in-context reasoning)和训练后推理(post-training reasoning):上下文推理通过结构化编排扩展了测试时的交互,而训练后推理则通过强化学习和监督微调来优化行为。 我们进一步回顾了涵盖科学、机器人技术、医疗保健、自主研究和数学等领域,在实际应用和基准测试中的代表性智能体推理框架。本综述将智能体推理方法综合成一个连接思维与行动的统一路线图,并概述了开放性挑战和未来方向,包括个性化、长周期交互、世界建模、可扩展的多智能体训练以及实际部署中的治理问题。
基础层
规划

LLMs如何通过规划来分解问题、安排决策并预测复杂环境。
分为情境内规划(In-context Planning)和后训练规划(Post-training Planning)。
情境内规划:在推理时设计和实施规划策略,而无需额外的模型训练。
- 工作流设计(Workflow Design):规划过程分为不同的阶段(如感知、推理、执行和验证)。如将任务分解为子任务,plan-act,task list的prompt。
- 树搜索/算法模拟(Tree Search / Algorithm Simulation):BFS、DFS、A*、MCTS和束搜索等树搜索算法来推理过程。
- 过程形式化(Process Formalization):通过符号表示、编程语言或逻辑框架来形式化规划,以确保组合性、可解释性和泛化能力。例如将计划编码为代码类工件或PDDL程序。
- 解耦/分解(Decoupling / Decomposition):将复杂的规划模块化为可分离的组件,例如目标识别、记忆检索和计划细化。ReWOO就是一个例子,它明确地将观察和推理模块分离以优化效率。
- 外部辅助/工具使用(External Aid / Tool Use):利用RAG、知识图谱、外部结构或世界模型和通用工具使用等来辅助规划。
后训练规划:通过优化方法来提升规划能力。
- 奖励设计/最优控制(Reward Design / Optimal Control):这种方法通过设计合适的奖励结构和使用强化学习或控制理论工具来解决最优行为问题。例如,Reflexion和Reflect-then-Plan等方法结合了基于效用的学习来指导规划行为,而其他工作则强调奖励塑形或明确处理最优控制问题。
工具
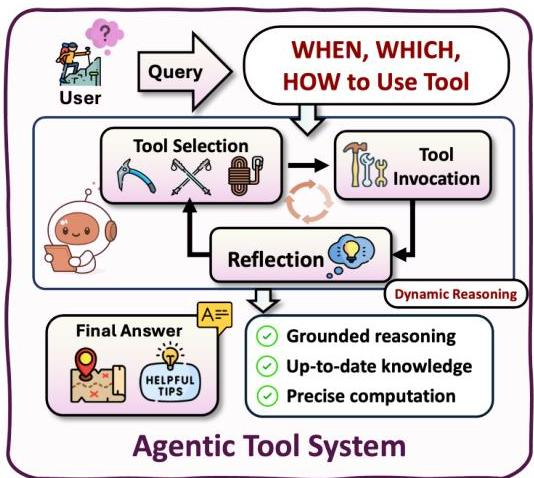
如何通过调用外部模块来增强其内在能力。
核心挑战在于智能体何时使用工具、选择哪个工具以及如何生成有效的调用。
分为三种主要类型:情境内工具集成、后训练工具集成和基于编排的工具集成。
情境内工具集成:无需训练,重点是设计在推理时的指令、示例和上下文信息,以引导LLM。
- 推理与工具使用的交错(Interleaving Reasoning and Tool Use):情境内智能体推理的基础在于通过采取action来增强CoT过程。如ReAct是reasoning+act,reasoning作用于行动计划,act作用于外部环境并从中收集信息。
- 优化工具交互的上下文(Optimizing Context for Tool Interaction):当智能体必须处理大量或复杂的工具集时,其性能会下降,需要优化这些上下文信息来解决这个问题。例如压缩上下文,截取长轨迹,明确的工具文档(使LLM能够以零样本方式使用新工具)。
后训练工具集成:作用于LLMs或大型检索模型(LRMs),学习如何与外部工具交互,将复杂任务分解为基于工具的推理步骤。
- 通过SFT引导工具使用(Bootstrapping of Tool Use via SFT):早期使用SFT训练。
- 通过RL掌握工具使用(Mastery of Tool Use via RL):最新研究利用RL。
基于编排的工具集成:实际应用中需要多个工具之间的编排来完成复杂任务,通常涉及规划、排序和管理工具间的依赖关系。
- 用于工具编排的智能体管道(Agentic Pipelines for Tool Orchestration):大多数当前Agent先plan后act,首先生成工具使用的结构化计划,然后执行它。如HuggingGPT 。
- 用于编排的工具表示(Tool Representations for Orchestration):侧重于优化工具本身,以促进在编排过程中更准确的选择、组合和协调。
搜索
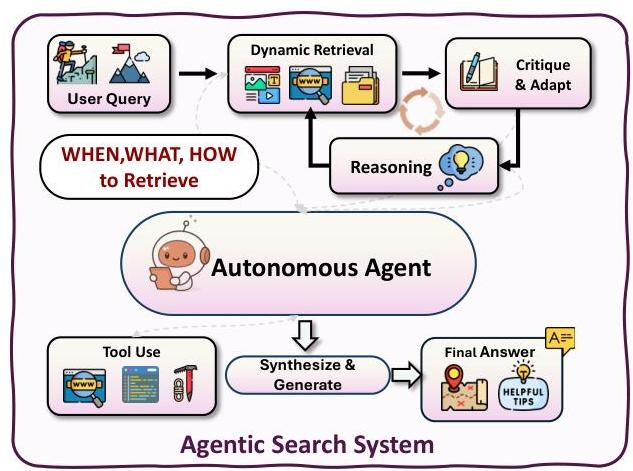
单智能体RAG系统分为三种不同的架构风格:情境内搜索、后训练搜索和结构增强智能体RAG 。
情境内搜索(In-Context Search):
- 推理与搜索的交错(Interleaving Reasoning and Search):通过精心设计的提示策略,将检索行为直接嵌入到语言模型的推理过程中,通过少量示例或特殊标记指导模型在单个前向传递中交替进行推理和搜索。如ReAct将思维链推理与工具使用命令(如
<Search>)交错,以动态调用外部API或知识源。 - 结构增强搜索(Structure-Enhanced Search):使单个智能体能够通过动态查询、工具调用和反射式自我监控来推理符号知识源(如知识图谱)。这些智能体决定何时访问结构化知识、如何制定基于图的查询以及检索到的信息是否足以继续推理轨迹。如Agent-G将非结构化文档检索与结构化图推理相结合,使用反馈循环和专门的检索模块来确保准确的多跳响应。
后训练搜索(Post-training Search):
- SFT驱动的智能体搜索(SFT-Driven Agentic Search)
- 基于RL的智能体搜索(RL-Based Agentic Search)
自进化智能体推理
反馈机制
分为三种不同的反馈模式:反思性反馈、参数适应和验证器驱动反馈。
反思性反馈(Reflective Feedback):通过自我批判或验证来修正其推理过程,而无需更新模型的参数。它暴露中间推理输出(如CoT或部分解决方案),并引入额外的评估步骤,直接影响模型如何继续生成。
参数适应(Parametric Adaptation):通过额外的训练将反馈整合到模型的参数,更新模型的权重。如对中间推理轨迹进行SFT或RL。
验证器驱动反馈(Validator-Driven Feedback):利用外部的成功或失败信号来改进模型输出,而无需修改模型的推理过程或参数。用一个验证器(如单元测试、约束检查器或模拟器)评估候选输出,并判断它们是否满足预定义的正确性标准。
记忆
记忆不再仅仅是延长上下文窗口或存储历史输入,而是被视为推理循环的一个不可或缺的组成部分,用于反思过去的经验、指导未来的行动以及动态适应复杂、长期的任务。
分为四种记忆方式:平面记忆的智能体使用、结构化记忆表示和训练后记忆控制。
平面记忆的智能体使用(Agentic Use of Flat Memory):
- 事实记忆(Factual Memory):传统的记忆系统主要将记忆用于存储对话历史或近期观察结果,以解决Transformer模型有限的上下文窗口问题。新兴的智能体记忆将其视为推理循环的一部分,支持反思和决策。
- 经验记忆(Experience Memory):工作流记忆会跟踪程序轨迹,以实现计划恢复和一致性推理。动态作弊表(Dynamic Cheatsheet, DC)则为黑盒模型配备外部记忆,以存储可重用策略,减少冗余推理。
结构化记忆表示(Structured Memory Representations):
- 如语义图、工作流和分层树,通常扩展到多模态设置,以更好地捕捉依赖关系和上下文关系。如GraphRAG通过图结构化RAG。
训练后记忆控制(Post-training Memory Control):
- 记忆系统也可以由智能体的推理过程本身控制,即智能体明确决定存储什么、何时检索以及如何与记忆交互。
进化的基础智能体能力
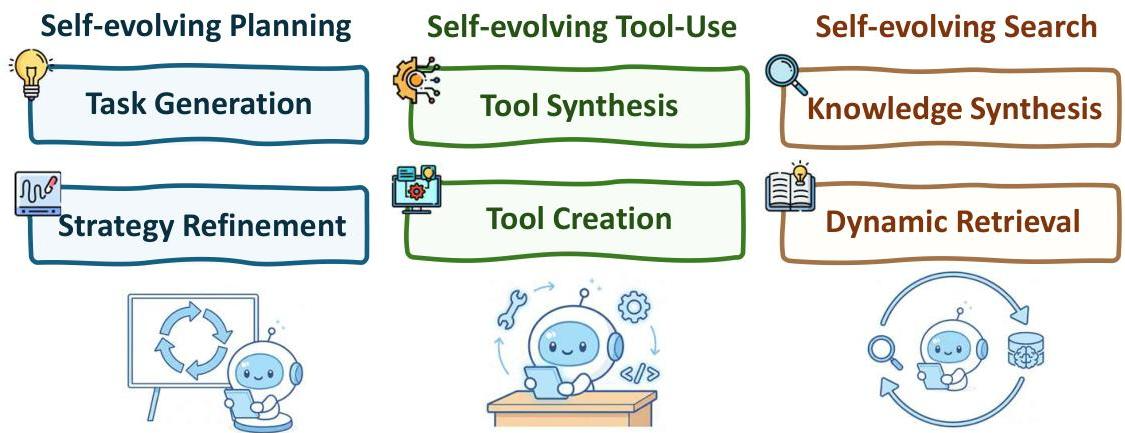
agent的核心能力(规划、工具使用和搜索)可通过自进化机制得到持续提升。
- 规划(Self-evolving Planning):
- 通过经验和反馈机制,自主地生成任务、完善策略并与环境进行迭代互动。
- 主要方向包括自生成任务构建,如SCA框架允许智能体交替生成和解决问题,并将成功的轨迹用于微调。自奖励框架使智能体能够评估自己的输出,产生高质量的训练信号。此外,智能体还可以通过环境塑造(如AgentGen构建自适应环境)或在线适应(如Reflexion和AdaPlanner)来进化,将自然语言的批判或轨迹转化为训练奖励,实现持续的策略完善。
- 自进化工具使用(Self-evolving Tool-use):
- 强调智能体能够自主创建和合成新工具。这不再仅仅是通过训练,而是通过提示一个冻结的大型语言模型,使其在遇到现有工具集无法解决的问题时,充当程序员的角色。
- 如LATM框架使用一个强大的模型作为“工具制造者”来创建工具,而一个更轻量级的模型作为“工具使用者”来频繁调用这些工具。CRAFT和CREATOR等框架则生成针对特定领域的定制工具。ToolMaker甚至可以将整个公共代码仓库转化为可用的工具,使智能体能够即时利用人类编写的复杂代码库。
- 自进化搜索(Self-evolving Search):
- 将搜索从静态工具转变为推理循环中不断适应的组成部分。 早期系统中搜索通常是静态的,依赖固定的检索启发式或基于相似性的检索器。而现在研究越来越将搜索和记忆联系在一个共同进化的循环中:智能体在任务执行期间持续更新其记忆库,同时动态调整搜索方式。
- 进化的记忆库(Evolving Memory Bases):智能体通过反思和执行后更新主动完善其记忆库。例如,Reflexion允许智能体批判自己的推理轨迹并存储提炼出的见解,从而提高未来的搜索相关性。
- 动态搜索和合成(Dynamic Search and Synthesis):搜索策略本身也可以通过动态优先级和合成来进化。结构化记忆表示(如工作流和知识图)提供语义支架,实现多跳和组合搜索。MemOS和Memory-as-Action等系统更是将搜索决策直接整合到推理策略中,使检索目标、策略和来源能够随智能体经验的积累而共同适应。
多代理协作推理
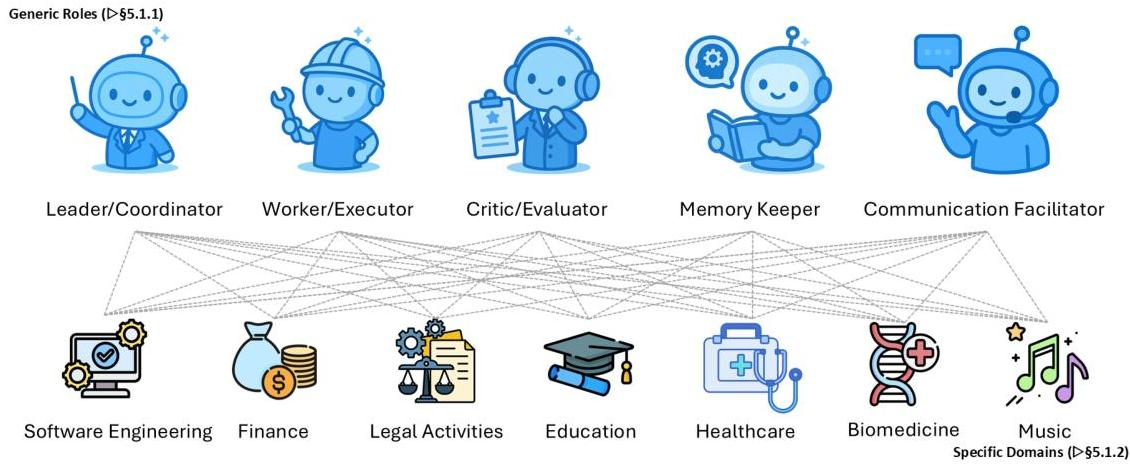
多智能体系统的角色分类
可分为通用角色和特定领域的角色。
通用角色(Generic Roles):
- 领导者/协调者(Leader/Coordinator):
- 设定全局目标、将任务分解为可管理的子目标、分配任务给智能体。
- 仲裁在具有重叠或矛盾输出的智能体之间出现的冲突。
- 工作者/执行者(Worker/Executor):
- 从事具体的行动,如调用外部工具、编写或执行代码、检索文档或与环境交互。
- 批评者/评估者(Critic/Evaluator):
- 验证正确性、测试假设、进行红队响应以及发现潜在风险。
- 在基于大型语言模型的系统中,通常对应于LLM-as-a-judge。
- 记忆维护者(Memory Keeper):
- 将记忆管理抽象为专门的角色。
- 整理和维护长期知识结构,如情景日志、语义嵌入、检索索引或知识图谱。
- 沟通协调者(Communication Facilitator):
- 沟通开销很容易损害多智能体系统的效率。
- 负责管理智能体间的交换协议,如定义消息模式、管理通信带宽、强制执行门控机制及协调共识建立。
领域特定角色(Domain-Specific Roles):特定领域的任务通常需要专门的功能。
- 软件工程(Software Engineering):多智能体系统通常映射到与软件开发生命周期相对应的角色:架构师、开发人员、代码评审员/测试人员、持续集成(CI)协调者和发布经理。
- 金融(Finance)
- 法律活动(Legal Activities)
- 法定推理(Statutory reasoning)
- 模拟法庭动态(Simulate courtroom dynamics)
- 医疗保健(Healthcare):
- 临床诊断和咨询(Clinical diagnostics and consultation)
- 自主研究(Autonomous research)
- 公共卫生事件(Public health events)
协作与分工
分为两个维度:上下文协作、训练后协作和智能体路由。
- 上下文协作(In-context collaboration):侧重于在推理时指定或诱导的协调策略,无需额外的训练。
- 训练后协作(Post-training collaboration):通过学习或搜索来优化智能体角色、交互结构或路由策略。
此外,智能体路由可以被视为分工的一种特殊情况,其中路由决策根据任务需求明确地将认知和计算卸载到不同的智能体。
上下文协作(In-context Collaboration):侧重于在推理时指定或诱导的协调策略,无需额外的训练。
- 手动设计的管道(Manually Crafted Pipelines):依赖于预定义的层级结构或固定的协作工作流,在执行前确定智能体角色、执行顺序和通信规则。
- 如 AgentOrchestra、MetaGPT 和 SurgRAW 有一个中央规划器或协调者通过结构化的子目标指导下属智能体。
- 级联管道(如 Collab-RAG、MA-RAG、Chain of Agents 和 AutoAgents)则顺序处理信息,将中间输出传递给下游,但修订有限。
- 模块化角色分解框架(如 RAG-KG-IL、SMoA 和 MDocAgent)定义了固定的功能角色。
- 大型语言模型驱动的管道(LLM-Driven Pipelines):利用LLM作为协调器将高级目标分解为子目标,将其路由到专业化的智能体或工具。如 AutoML-Agent,Magentic-One,MAS-GPT。
- 智能体路由(Agent Routing):与LLM驱动的编排密切相关,它明确将智能体路由建模为一个决策层,为每个查询或子任务选择合适的专家。 如AgentRouter,Talk to Right Specialists 。
训练后协作(Post-training Collaboration):通过学习或搜索过程优化智能体的角色、交互结构或路由策略。
多智能体进化
通过强化学习、自博弈、课程演化和验证器驱动的反馈等方式。
分为:从单智能体演化到多智能体演化、多智能体记忆管理与演化和训练多智能体以演化。
从单智能体演化到多智能体演化:
- 幕内演化(Intra-test-time evolution):在任务执行期间适应和改进的能力。如自然语言自我批评、运行时自适应规划和记忆重写等方法,不进行外部监督。
- 幕间演化(Inter-test-time evolution):将自我改进过程扩展到跨任务学习,其中在一个任务中进行的适应可以被巩固并转移到未来的任务中。包括离线自我蒸馏、在线强化学习框架和课程机制等方法。
多智能体记忆管理与演化:
- 架构:Memory用三层图层次结构区分高级通用洞察和细粒度执行轨迹,Intrinsic Memory Agents为每个智能体维护专用的与角色对齐的记忆模板。
- 存储拓扑与记忆治理:介绍了集中式、分布式和混合式存储。
- 记忆内容:语义、任务和认知阶段分解等
- 记忆管理策略:基于遗忘的方法(例如“总结与遗忘”)、结构化管理(将过程跟踪组织成结构化三元组)以及学习型方法(通过强化或模仿学习优化记忆使用)等。
训练多智能体以演化:
- 通过交互和内在反馈进行协同演化:通过明确的训练目标实现多智能体演化。
- 用于集体适应的多智能体强化微调:基于LLM的多智能体系统量身定制的强化微调框架。
- 角色专业化和联合信用分配:结构化角色专业化和联合信用分配的方法。
- 偏好驱动和对齐驱动的多智能体演化:将人类反馈或强化学习与人类意图对齐。
未来挑战
用户中心化智能体推理和个性化 (User-centric Agentic Reasoning and Personalization)
长期智能体推理和扩展交互 (Long-horizon Agentic Reasoning from Extended Interaction):目前的模型在长任务中错误会迅速累积,需要更细粒度的信用信号和跨多个情节和任务的泛化学习方法。
世界模型下的智能体推理 (Agentic Reasoning with World Models):世界模型的设计依赖于临时表示,并且通常在短期或特定环境数据上进行训练。
多智能体协作推理与训练 (Multi-agent Collaborative Reasoning and Training):扩展到更大规模的智能体群体会引入拓扑适应、协调开销和安全等挑战。
潜在智能体推理 (Latent Agentic Reasoning):潜在智能体推理探索在内部潜在空间而不是显式的自然语言或符号跟踪中执行规划、决策和协作。虽然潜在推理可以提高效率和可扩展性,但代价是可解释性和可控性降低。
智能体推理的治理 (Governance of Agentic Reasoning)