https://arxiv.org/abs/2510.18234
1 引言
当前的LLMs在处理长文本时,计算复杂度与序列长度呈二次方增长,导致巨大的计算挑战。二次方增长是由Attention的计算方式导致的,除非改进结构,否则很难避免。
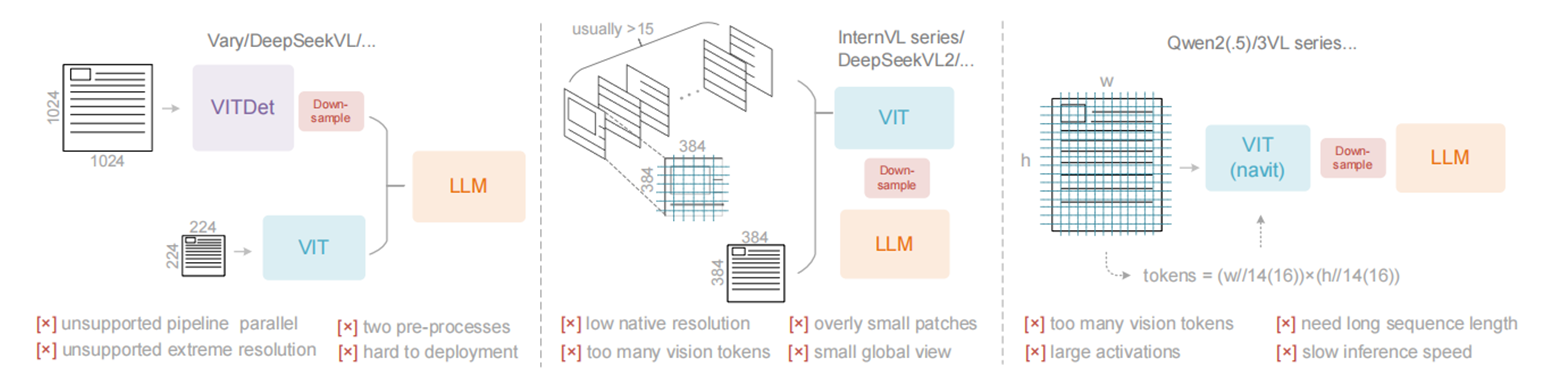
目前主流的VLMs为了缓解这个问题,使用了如双塔架构、基于分块的方法和自适应分辨率编码等架构,但都仍然存在着不足,例如Vary等双塔架构难以支持 pipeline parallel,基于分块的方法和自适应分辨率编码都会生成过多的vision tokens,或者激活内存消耗极大,引发GPU显存溢出。
针对这个问题,deepseek-ocr的作者提出:能否把文本用图片的形式压缩,以减少token的数量?如果能够在压缩token的情况下依然能保存和压缩前几乎相同的信息量,就说明这个方法是可行的。值得补充的是,ICLR 2023 的《Language modelling with pixels》可能是第一篇讨论如何把文本变成图像然后用ViT理解它的paper,并且由于不需要基于character模型中过长的sequence,从而解决了vocabulary的瓶颈。DeepSeek-OCR在理论方面可能不算突破,但具有一定工程价值。

2 架构
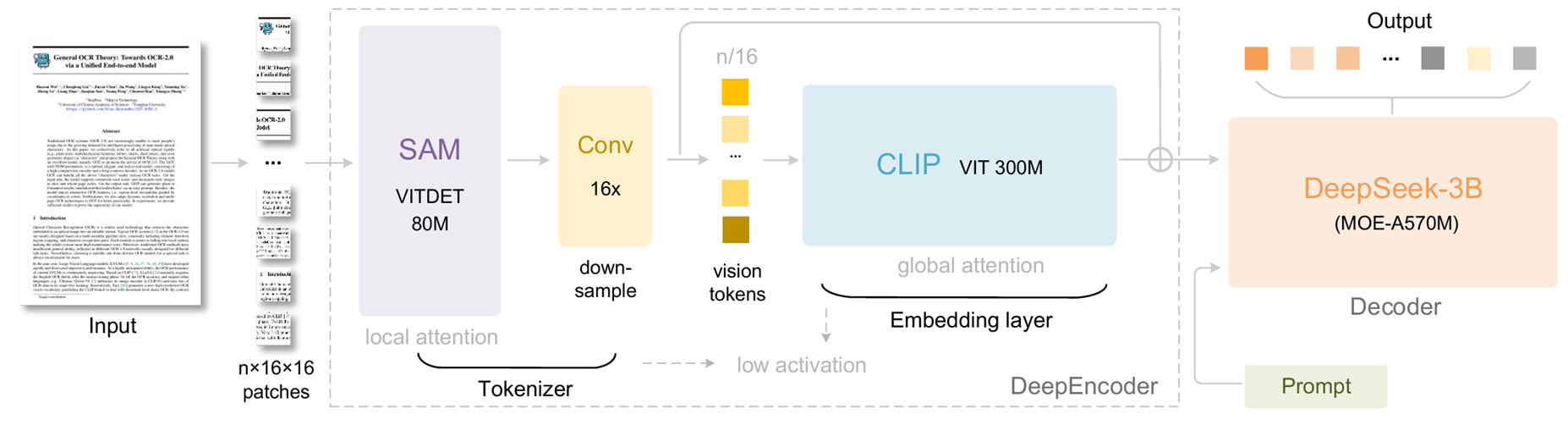
架构图看上去是输入image、输出文字的工作,但DeepSeek-OCR最终想讨论的其实是能否通过压缩输入token数来缓解计算开销的问题,所以在image输入之前,其实还有一个工作就是把text转化为image,然后才是对image做处理。
DeepSeek-OCR由encoder和decoder两个部分组成。encoder是光学压缩的重点,分为SAM和CLIP,中间包括了卷积层进行下采样。
Encoder的网络架构,基于一作(Haoran Wei)于23年发表的paper《Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models》。Vary的核心想法是用SAM和CLIP这2个image encoder抽取feature,最后融合起来。DeepSeek-OCR的改进在于,把Vary的并行结构改成了串行结构,先用SAM和卷积层对image做处理,再把输出送到CLIP进行处理。
2.1 DeepEncoder
2.1.1 SAM-base
SAM-base是视觉感知特征提取模块。
原始图像被切分为n个16*16的patch(图像)后,输入给SAM。SAM使用window attention来提取局部特征,SAM输出vision tokens。
这里的SAM-base并不是原版的SAM,而是何恺明提出的ViTDet:把global attention改成了local attention(也就是window attention),这样做的好处是在尽可能高的输入分辨率下,用尽可能少的activation memory和vision tokens,同时不损失关键信息。
因为不同的文档和图像复杂度差异巨大,DeepSeek-OCR 希望在“清晰度”和“计算成本”之间自由切换,从而在不牺牲性能的前提下实现更高效的推理,所以引入了多分辨率支持。对于简单的图,就用小的分辨率转换为较少的tokens;对于复杂的图,就转换为较多的tokens。这个多分辨率支持的机制与24年的 NeurIPS《Visual Autoregressive Modeling》也很相似,这篇paper采用了“由粗到细”的多尺度预测方式——先低分辨率生成,再逐步提升清晰度。同时也展示了相同的数据压缩路径:512×512 图像可编码为 64 个 token,256×256 甚至能压到 32 个 token。
2.1.2 Conv(down-sample)
下采样用2 stride=2的卷积层,把SAM输出的特征图的空间分辨率缩小16倍。
stride=2:卷积核每次移动 2 个像素,相当于隔一个取一个;输出的宽、高都会变成原来的一半,面积缩小为原来的 1/4。
2个卷积层:(1/4)×(1/4)=1/16
如果输入是SAM提供的 4096个 vision tokens,经过下采样后vision tokens可以降到256个。通过减少tokens,使整体激活内存处于可控状态,让高分辨率图像处理变得可行。
2.1.3 CLIP-large
CLIP是视觉知识特征提取模块。SAM获取下采样后的vision tokens,通过global attention让每个vision token和所有其他token全局交互,这样既有SAM的局部信息计算,又有CLIP提供的全局信息计算。
2.1.4 总结
通过上述的设计,DeepEncoder能够处理高分辨率图像,且在高分辨率下激活内存低,这是因为SAM 使用 window attention,每个窗口独立计算,只在局部区域传播信息,因此降低了激活内存,不会因为分辨率升高而让注意力矩阵爆炸。另外,通过卷积层的下采样,也减少了vision token数量,可以将4096个tokens可以减少到256个。
2.2 DeepSeekMoE
decoder则使用了DeepSeek-MoE模型。
DeepSeek-MoE输入是:
- encoder输出的视觉特征向量序列;
- 文字prompt,指示模型要执行哪种 OCR / 文档解析任务。
输出是下一个token的概率分布(文本序列)。
参数量而言,虽然MoE是3B的模型,但推理时实际激活参数只有570M,激活了64个路由专家中的6个,以及2个共享专家。
3 Training
3.1 Training Data
训练模型的数据约70%是OCR数据,OCR1.0主要是如场景图像OCR和文档OCR等传统的OCR任务,这其中包含了互联网的多语言 PDF 数据,使DeepSeek-OCR自然具备了多语言识别的能力。OCR2.0包括了图表、化学公式和平面几何解析数据等复杂的人工图像。
3.2 Training Pipelines
首先,单独训练DeepEncoder,做next-token prediction。
然后,用Pipeline Parallelism训练deepseek-ocr整体,使用了HAI-LLM 框架。在这一阶段里冻结了SAM和卷积层的参数,继续训练CLIP和Decoder部分。
最后,如果需要进一步训练gundam-master模式的话,就在已预训练的DeepSeek-OCR模型上使用600万条采样数据继续训练。Gundam-Master模式是其中一种超高分辨率动态输入模式,用于处理如报纸、大幅面PDF等复杂的文档,其核心设计目标是在保持高OCR精度的同时,避免因单图分辨率过大而导致显存溢出或训练不稳定。
4 分析
4.1 Vision-text Compression Study
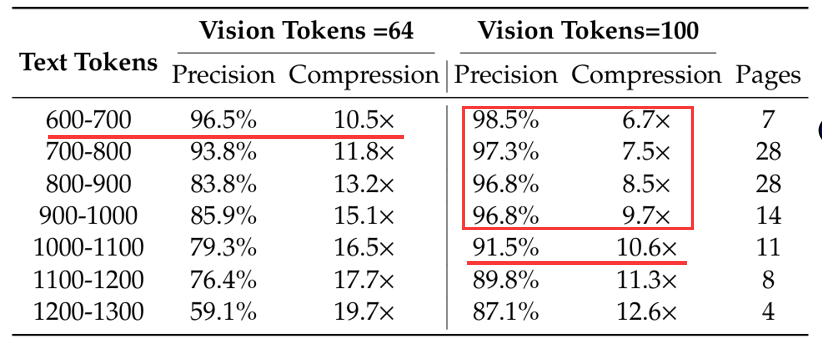
回到一开始提出的问题:一张图像(视觉表示)到底能压缩多少文字信息而不丢失内容?实验的输入是不同数量级的text,用precision衡量模型输出的text和真实text的匹配度。实验分为2种情况,分别是将text压缩后输出64个vision tokens,以及压缩后输出100个vision tokens。
实验用了Fox做了benchmark。当600-700个text tokens的文档压缩为64个vision tokens后,压缩率达到10.5倍,精度仍在96.5%;而如果是压缩率为10倍以下的情况精度可达97%。但是当压缩比超过10倍时,性能开始下降。
4.2 OCR Practical Performance
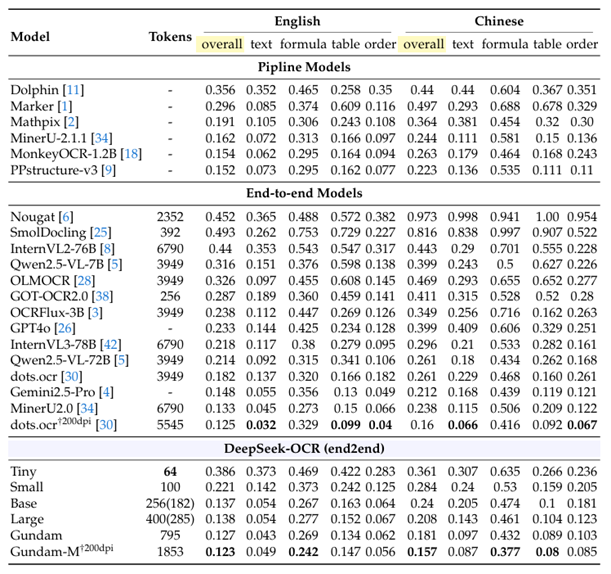
这个实验用了OmniDocBench做benchmark。
实验把当前OCR模型分为3类。第1类是传统的OCR模型,是多步骤的pipeline,比如第一步做layout detection(哪些地方有文字,哪些地方是图表),第二步是对每个部分做文字识别,这里每一步都可能出错,且上一步的错误可能会影响下一步的精度。第2类是end2end的主流的VLM,其中表现最好的是小红书的dots.ocr。第3类就是DeepSeek-OCR系列模型。
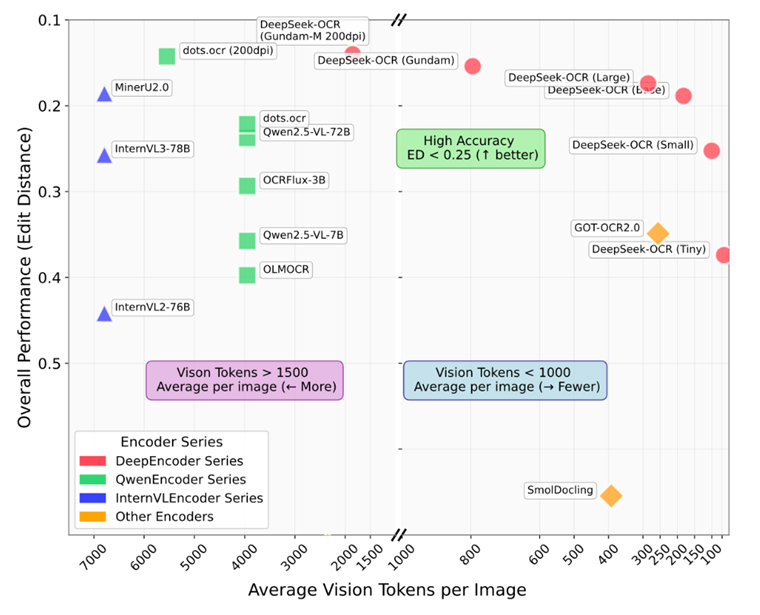
下图横坐标表示平均使用的tokens,越靠右越少;纵坐标表示模型的表现(edit performance),越往上越好。DeepSeek-OCR虽然性能上没有非常夸张地超过SOTA,但是它能以更少的vision token 达到近似或以微弱优势超过主流 OCR 模型的精度。
4.3 遗忘机制
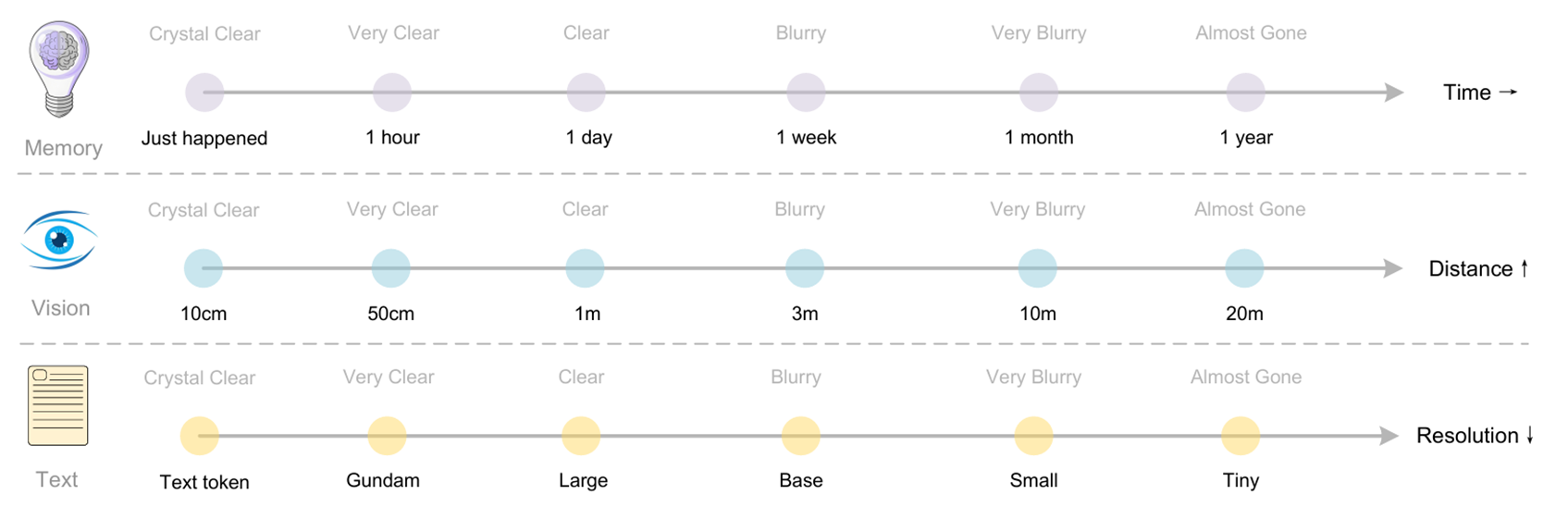
这篇paper的创新点并不只在OCR,或者说,这篇paper在做完OCR的工作后升华到了人类记忆的遗忘机制,认为光学压缩可以类比遗忘机制,而这种遗忘机制可以处理长context。(或许可以从这篇paper学习一下如何拔高立意hh)
注意论文讨论的压缩对象是token,而不单纯是information。如果是information的话,对context进行summary或者摘要也可以做到“压缩”。vision token可以被下采样,而text token难以做到:一句话如果少了10%的单词,就已经难以理解了。
讨论:对于最近的对话,可以把它转换为较高分辨率的picture;随着对话的进行,该对话逐渐变得古老,我们可以压缩这个古老的picture,为memory腾出更多的空间。这就类似于人类的记忆,对于刚刚发生的事情还能记住很多细节,而童年的回忆只剩下一个模糊的轮廓。
5 讨论
论文虽然论证了deepseek-ocr压缩的效果很好,但这里主要讨论一下Encoder压缩是否真实。这个问题在社区受到一定程度的质疑。
-
未具体讨论 decoder 的贡献
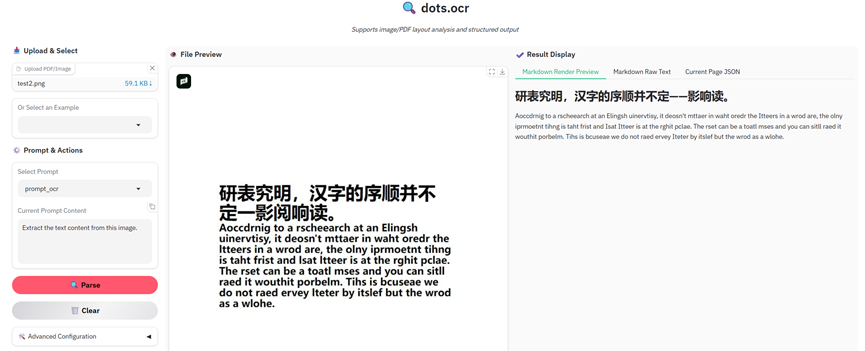
我在使用deepseek-ocr的时候发现,输入的图片内容是“汉字的序顺并不定一影阅响读”,但是OCR的推理结果是“并不一定一影响阅读”。在InternVL上也会出现类似的情况(见后),这或许是end2end的OCR模型都存在的问题:不仅是识别字符,还包括了语言理解或者纠正机制。我个人觉得这是decoder在自动补全语言信息的体现。
如果 vision token 缺少某些细节,decoder 完全可能通过语言学prior自动补上,使得结果看起来几乎无误。这是因为LLM 具有强语言先验(Language Priors),例如猜字、补全句子、根据上下文恢复缺失的信息。所以重建精度高不代表encoder存储了全部信息。
-
缺少 stage 1 的消融实验
论文中,Stage1用轻量decoder训练encoder;Stage2在此基础上训练decoder,并报告了Satge 2之后的模型效果,但唯独没有报告Stage1的encoder效果。如果压缩是真实的,那么Stage1应该表现很好。但文章中没给出对应的结果,所以:无法证明encoder压缩是真实的,或者说,压缩能力是来自encoder的高质量表征,还是来自 Stage2中强decoder的语言补全能力,无法被直接区分。
如果这里要做消融实验的话,我的一个想法是:在相同视觉压缩率(如64或100vision tokens)下,分别测量 Stage1和Stage2的OCR精度。若Stage1已经能够在高压缩率下取得接近Stage2的性能,则说明encoder的压缩能力占主导;反之,若Stage1明显劣于Stage2,则表明最终的精度有相当部分来自decoder的语言先验与补全能力,而非encoder本身的压缩表示质量。
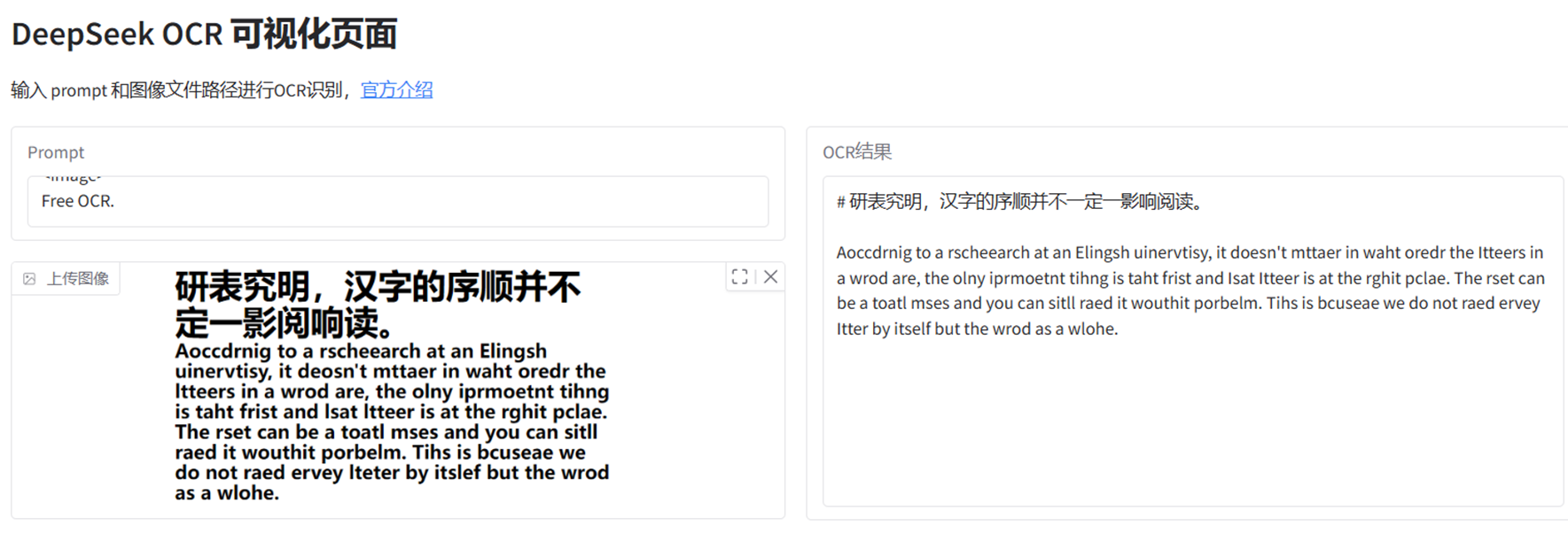
【附录】end2end的OCR模型“并不定一影阅响读”的测试情况
InternVL3.5
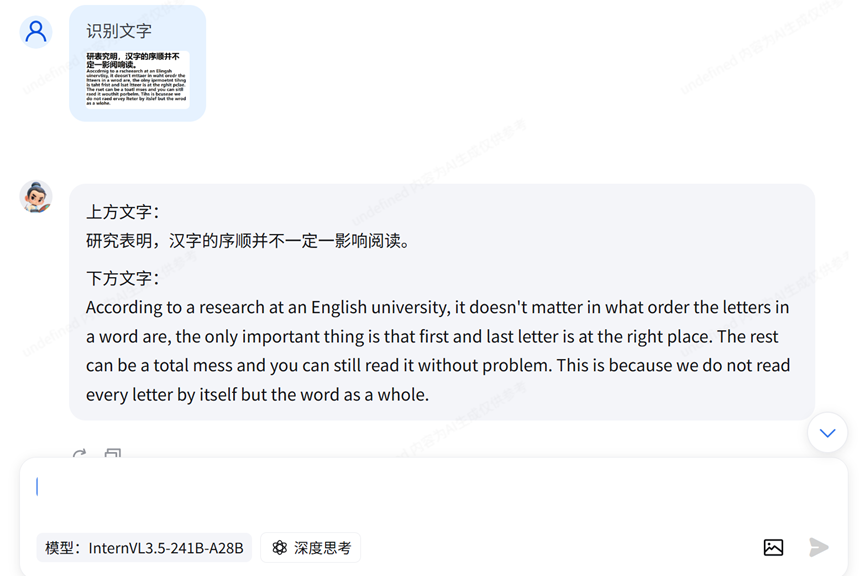
Qwen3-VL

Dots.ocr