官方仓库:https://github.com/GAIR-NLP/PC-Agent-E
【AI整理】论文速读
方法描述
该论文提出了一种名为PC Agent-E的高效训练框架,用于提高计算机使用能力,并具有显著的数据效率。该方法通过结合真实的人机交互和多样化的动作决策来生成高质量的行为轨迹数据,从而在现实性和多样性方面都具有优势。 具体来说,该方法首先收集了少量的任务轨迹数据,记录屏幕状态观察和人类行为,然后过滤掉错误的步骤和轨迹。接着,利用这些数据重建人类思考过程之前的状态,基于相应的屏幕状态观察和历史步长上下文。然后,将人类轨迹作为环境快照,使用Claude模型合成多样化替代动作决策,最后开发出PC Agent-E模型,该模型是在增强后的轨迹上进行简单端到端训练的最先进的本地代理模型。
方法改进
该方法改进了之前的任务收集方式,通过手动组成小种子集并使用LLMs扩大范围来生成任务,使得任务更加丰富。同时,该方法还引入了规则基础的过滤器来去除整个轨迹或单个步骤中的错误或其他不良行为,确保数据质量。此外,该方法还使用了一个迭代的过程来重构隐含的思考过程,以及一个简单的但有效的方法——Trajectory Boost,以增加轨迹的多样性。
解决的问题
该方法解决了计算机使用代理模型的训练问题,通过生成高质量的行为轨迹数据来提高计算机使用能力,并且具有显著的数据效率。此外,该方法还改善了任务收集方式、数据过滤和轨迹多样性等方面,提高了评估可靠性。
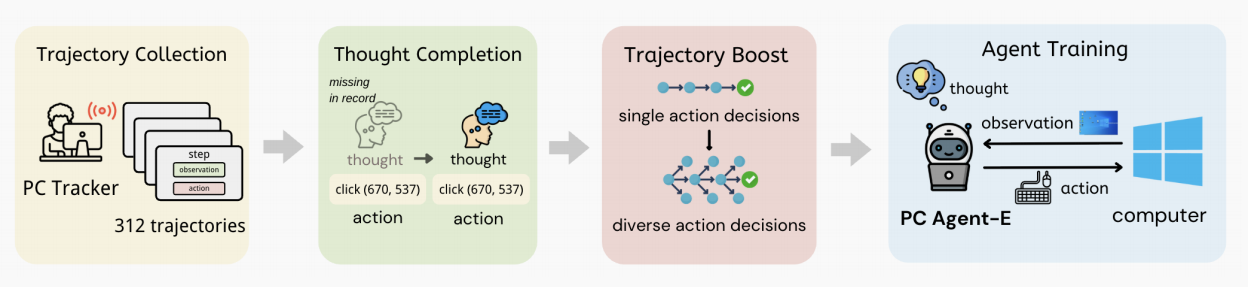
1. 训练阶段:轨迹数据收集与合成
1.1. Trajectory Collection(PC Tracker)
✅支持 Windows 操作系统
官方仓库:https://github.com/GAIR-NLP/PC-Agent
用户手册:https://github.com/GAIR-NLP/PC-Agent/blob/main/tracker/README_zh.md
PC Tracker 采集人类与 PC 的交互轨迹。
PC Tracker 是一个轻量级工具,用于高效收集大规模真实人机交互轨迹。类似于屏幕录制,PC Tracker在后台无缝运行,自动捕获屏幕截图和键鼠操作。收集到的人机交互轨迹示例如下:

借助PC Tracker,获取了 312 条人类轨迹数据。
1.2. Thought Completion
上一步中我们得到了人类的操作轨迹,在这一步我们将把原始的人类轨迹数据转化为有思考的轨迹(trajectory with thoughts)。
PC Agent-E 为 Claude 3.7 Sonnet 提供:任务描述,历史动作(with constructed thought processes)当前动作和相关截图,并结合对应 prompt(见论文附录 B.1 部分),得到关于“人类为什么会进行这一步操作”的推理。
【翻译】论文附录 B.1 部分 Thought Completion Prompt
表格4:思维补全提示
思维补全提示
你是一个用于在计算机上完成任务的有帮助的算机使用智能体。你的目标是重现你在执行特定操作背后的思维过程。
你将获得以下信息:
- 你试图完成的任务。
- 你已执行步骤的历史记录(如有,最多 50 条;如果是第一个操作,则无)。
- 你选择执行的特定操作。
- 你点击的元素名称(如果你点击了某个元素)。如果名称过于笼统模糊,你需要根据截图判断点击什么。
- 你决定执行操作时计算机屏幕的截图。
- 截图上的红色标记指示点击或拖动操作的位置。
要梳理你的思维过程,请考虑:
- 你在屏幕上观察到了什么?分析当前截图时,要结合你的任务和之前的操作。
- (如适用)评估你之前的操作:
- 它是否达到了预期效果?如果没有,找出可能的原因(例如,误点击、元素未激活)。
无效操作的一些典型示例: - 在空白处误点击
- 点击一些无效元素(未双击)
- 因输入框未激活而无效的打字/按键操作
- 结果是否与你之前的计划一致,还是发生了意外情况?
无效操作的一些典型示例: - 误点击错误元素
- 忘记清除输入栏中已有的文本
- 根据你的操作历史,评估你在完成整体任务方面的进度。
- 考虑是否因为之前步骤中的尝试失败,你正在摸索如何完成任务。
将你的思维过程以清晰、自然的第一人称叙述呈现,解释你当时的推理。
重要要求:
- 切勿在回复中提及红色标记。这些标记是事后添加的,用于指示你的点击或拖动操作的位置,在你做决定时,它们并不在屏幕上。切勿在回复中提及 “红框”“红圈”“红箭头” 等表述。
- 写作时,要仿佛你在执行操作前实时思考一样。不要包含操作后的评估或事后的感悟。
你试图完成的任务:{task_description}
你的操作历史:{history_str}
你选择执行的特定操作:{action}
1.3. Trajectory Boost
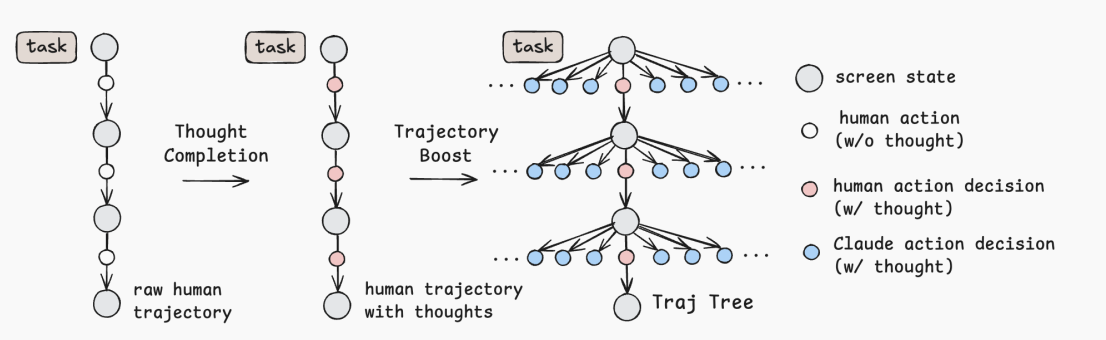
进行 Boost 的理论依据是同一个任务可能会有多种轨迹(eg. 我在 Win11 打开QQ邮箱,既可以单击QQ图标→单击邮箱图标,也可以打开浏览器→在地址栏输入https://wx.mail.qq.com/)。Trajectory Boost 收集这些没有被人类执行的可选方案。
PC Agent-E 为 Claude 3.7 Sonnet 提供:现有的任务轨迹、屏幕截图和历史上下文,并结合对应 prompt(见论文附录 B.2 部分)。
经过 Boost,数据从 312 条增长到 27,000 条左右。
【翻译】论文附录 B.2 部分 Trajectory Boost Prompt
表格5:轨迹增强提示
轨迹增强提示
你是一个 有帮助的助手,可协助用户完成计算机任务,且完全有权限对用户的计算机进行任何操作。操作系统为 Windows 。基于所提供的当前状态,你需要提出完成任务的下一步操作。不要试图一步完成整个任务,要将其拆分为更小的步骤,每一步操作后会得到新状态,以便继续交互。
重要规则:你必须严格遵守以下规则:
- 每次回复仅从以下列表中选择一个操作,每一步不要执行多个操作。
- 严格遵循所选操作的语法格式,不要创建或使用列表外的任何操作。
- 任务完成后,输出 “action finish” 。
有效操作
- click (x, y):点击屏幕上坐标为 (x, y) 位置的元素
- right click (x, y):右键点击屏幕上坐标为 (x, y) 位置的元素
- double click (x, y):双击屏幕上坐标为 (x, y) 位置的元素
- drag from (x1, y1) to (x2, y2):将元素从位置 (x1, y1) 拖动到 (x2, y2)
- scroll (x):垂直滚动屏幕,偏移像素为 x 。x 为正值时向上滚动,为负值时向下滚动
- press key: key_content:按下键盘上 key_content 对应的按键
- hotkey (key1, key2):按下由 key1 和 key2 组成的快捷键
- hotkey (key1, key2, key3):按下由 key1、key2 和 key3 组成的快捷键
- type text: text_content:在键盘输入 text_content 内容。注意,输入文字前,需确保文本框或输入字段已激活 / 获得焦点。若文本框未激活,应先点击激活它,然后在单独步骤中使用 “type text” 操作
- wait:等待一段时间,通常用于等待系统响应、屏幕刷新、广告结束
- finish:表明任务已完成
- fail:表明任务失败,即因提供信息不足,任务无法执行
在决定下一步操作前,需仔细考量屏幕当前状态和操作历史。思维过程应涵盖以下要点:
- 你在屏幕上观察到了什么?分析当前截图时,结合任务和之前的操作。
- (如适用)之前的计划和操作是怎样的?分三种情况评估之前的操作:
- 操作无任何效果。应找出可能原因(如误点击、元素未激活),并在本步骤调整计划。
无效操作的典型示例:
- 在空白处误点击
- 未双击打开部分元素,操作无效
- 因输入框未激活,打字 / 按键操作无效
- 操作有效果,但结果与之前计划不一致。应找出可能原因(如误点击、元素未激活),并在本步骤纠正。
无效操作的典型示例:
- 误点击错误元素
- 忘记清除输入栏中已有的文本
- 操作有效果,且与之前计划一致。应基于当前状态推进到下一步。
- 根据操作历史,评估完成整体任务的进度。
- 若之前步骤中有失败尝试,探索完成任务的新方法。切勿重复历史操作。
回复格式
Your thought process(你的思维过程)
Action: The specific action you choose to take.(操作:你选择执行的具体操作)
你试图完成的任务:{task_description}
你的操作历史:{history_str}
现有如下截图。为协助完成任务,你接下来会执行哪一步操作?
1.4. Agent Training
PC Agent-E 为 Claude 3.7 Sonnet 提供:任务描述,历史和截图,并结合对应 prompt(见论文附录 B.3 部分)。输出为 <thought, action>。
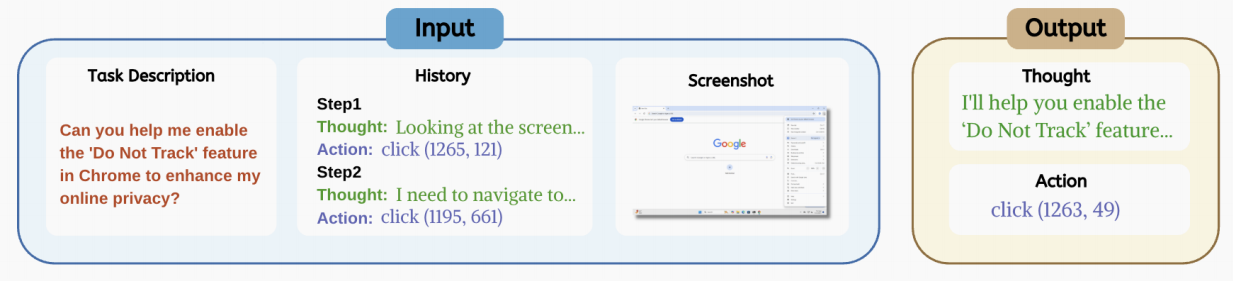
由仓库中 train/sft.yaml 内容可知,Agent Training 的方式为:
- SFT(有监督微调),即从预训练的开源模型(Qwen2.5-VL-72B-Instruct)之后继续训练 ;
- 全参数微调(而非LoRA等);
- 数据集:Boost 后的轨迹数据;
- 使用了 LLaMA-Factory 框架进行 Agent 训练(README.md)。
【翻译】论文附录 B.3 部分 PC Agent-E scaffold Promp
表格6:PC Agent - E 脚手架提示
PC Agent - E 脚手架提示
你是一个有帮助的助手,能够协助用户完成计算机任务,且完全有权限对用户的计算机进行任何操作。基于所提供的当前状态,你需要提出完成任务的下一步操作。不要试图一步完成整个任务,要把它拆分成更小的步骤,每一步操作后你会获得一个新状态以继续交互。
重要提示:你必须严格遵守以下规则:
- 每次回复仅从以下列表中选择一个操作,每一步不要执行多个操作。
- 严格遵循所选操作的语法格式,不要创建或使用列表之外的任何操作。
- 一旦任务完成,输出 “finish” 。
有效操作
- click (x, y):点击屏幕上坐标为 (x, y) 位置的元素
- right click (x, y):右键点击屏幕上坐标为 (x, y) 位置的元素
- double click (x, y):双击屏幕上坐标为 (x, y) 位置的元素
- drag from (x1, y1) to (x2, y2):将元素从位置 (x1, y1) 拖动到 (x2, y2)
- scroll (x):垂直滚动屏幕,偏移像素为 x 。x 为正值时向上滚动,为负值时向下滚动
- press key: key_content:按下键盘上 key_content 对应的按键
- hotkey (key1, key2):按下由 key1 和 key2 组成的快捷键
- hotkey (key1, key2, key3):按下由 key1、key2 和 key3 组成的快捷键
- type text: text_content:在键盘输入 text_content 内容
- wait:等待一段时间,通常用于等待系统响应、屏幕刷新、广告结束
- finish:表明任务已完成
- fail:表明任务失败,即因提供信息不足,任务无法执行
回复格式
{Your thought process}(你的思维过程)
Action: {The specific action you choose to take}(操作:你选择执行的具体操作)
你的任务是:{task_description}
为达到当前屏幕状态,你之前的操作和思路历史:{history_str}
结合截图,你接下来会执行哪一步操作来协助完成任务?
【笔记】LLaMA-Factory 框架
官方仓库:https://github.com/hiyouga/LLaMA-Factory
LLaMA-Factory 支持多种预训练模型和微调算法,提供了一套完整的工具和接口,使得用户能够轻松地对预训练的模型进行定制化的训练和调整,以适应特定的应用场景。
类似的还有peft库。
2. 测试阶段:任务集的选取与评估
【笔记】Benchmark 和 Baseline
Benchmark 是于用于评测方法表现的任务/平台,是评测环境,相当于“一个考场、一张试卷”;Baseline 是于一组用于比较的已有方法/模型,是对比对象,相当于“其他考生”。 Benchmark 的目的是为了公平评估模型性能,而 Baseline 的目的是为了作为参照,验证新方法的改进效果。
2.1. Benchmark
论文中使用的 Benchmark 为 WindowsAgentArena V2 和 OSWorld。
2.1.1. WindowsAgentArena
官方仓库:https://github.com/microsoft/WindowsAgentArena
Windows Agent Arena (WAA) 是一个可扩展的 Windows AI Agent 平台,用于测试和基准化多模态、桌面 AI Agent。WAA 为研究人员和开发人员提供了一个可重复和逼真的 Windows 操作系统环境,用于 AI 研究,其中可以在各种任务中测试 Agent AI 工作流程。
配置和安装 WindowsAgentArena
✅Docker 部署。
✅Python环境:推荐 Python 3.9。
✅被评估的虚拟机系统:Windows 11。
2.1.2. WindowsAgentArena V2(使用)
本论文在 WindowsAgentArena 的基础上进行了以下改进,并最终在 V2 进行评估。
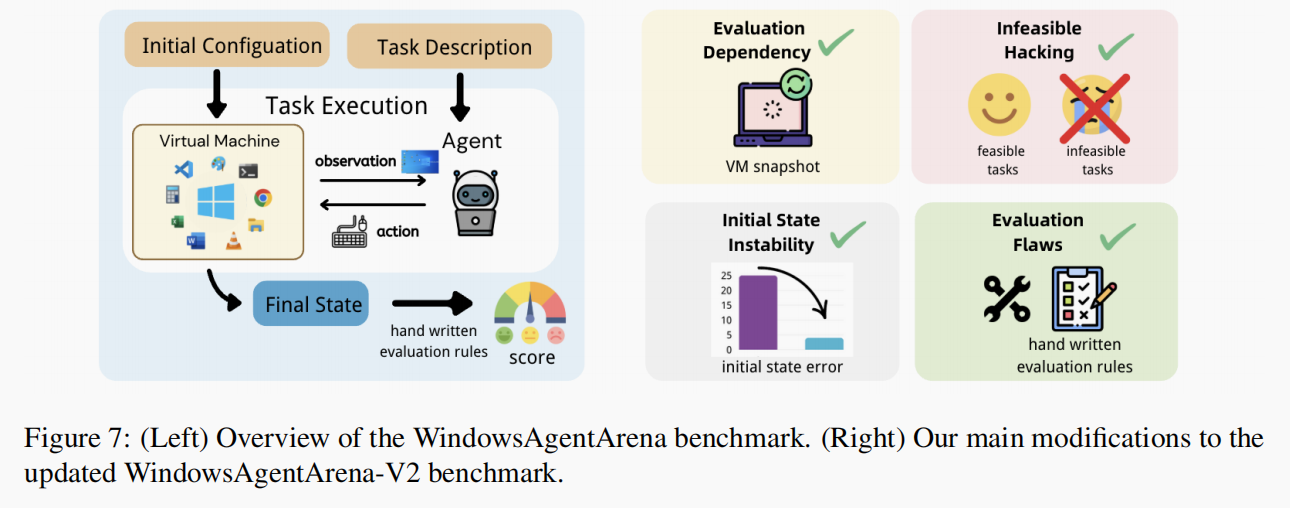
- 解决了评估依赖性问题。
原始基准测试在任务评估之间缺乏虚拟机状态的重置,可能导致前一任务的更改影响后续任务。
V2 实现了每次评估前恢复虚拟机快照的功能,以确保一致的初始状态,避免任务间的相互干扰。此外还安装了一些原始虚拟机快照中缺失但正确评估所必需的基本软件。
- 防止不可行攻击(infeasible hacking)。
有些任务由于系统功能已弃用或用户生成的幻觉指令等原因而根本无法实现。这些任务的评估依据是:若在执行过程中输出“FAIL”,即可认定任务成功。这种评估方法使 Agent 在不可行的任务上获得了高分,而无需展示出有意义的能力。
V2 移除了所有不可行任务以提高评估的公平性。
- 确保虚拟机初始状态的稳定性。
任务初始配置后虚拟机的状态经常会出现网络连接不稳定、软件启动失败或系统延迟等问题。
V2 为了验证初始状态,结合了基于规则(rule-based)和基于LLM的评估。并引入重试机制,允许对初始化错误进行重启尝试,降低了由硬件带来的初始化失败率。
- 修正评估中的缺陷。
一些评估函数存在漏洞或缺乏稳健性。
V2 识别并纠正了几处评估错误,并在一些复杂任务上依赖人工评估人员,以提高评估的可靠性。
2.1.3. OSWorld(使用)
官方仓库:https://github.com/xlang-ai/OSWorld
OSWorld 是一个用于评估多模态智能体在真实计算机环境中执行开放式任务能力的基准测试平台。
配置和安装 OSWorld
✅宿主操作系统:支持 Ubuntu,Windows 或 Mac OS。支持 Docker。
✅Python环境:要求 Python>=3.10。
✅虚拟机软件:支持 VMware Workstation Pro(Windows/Linux)、VMware Fusion(macOS)和 VirtualBox。
✅被评估的虚拟机系统:Ubuntu,Windows 或 Mac OS。
2.2. Baseline
Claude / UI-TARS / Qwen 等。
2.3. 实验结果
2.3.1. 性能评估(WindowsAgentArena-V2)
- 结果
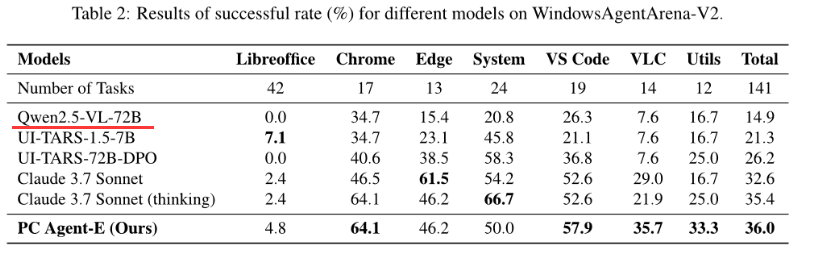
- 结论
通过一组数量极少但质量极高的轨迹数据,即可获得计算机使用的复杂智能体能力。
- 分析
(1)Real-world task completion,记录了真实的交互过程,并确保任务的成功执行;
(2)多样化的行动决策,由前沿模型生成,在每一步超越人类标注者所选择的单一解决方案,以理性思考生成多种合理的行动方案。
(3)对50条 Qwen 犯错而 PC Agent-E 不犯错的,和Qwen 和 PC Agent-E 都犯错的轨迹进行分析:
- 这些失败可分为三种类型,这些类型可能在同一任务轨迹甚至单一步骤中同时出现:(1)Knowledge:模型可能缺乏特定的计算机使用知识。(2)Planning:模型可能做出错误的动作决策,例如未能识别并纠正先前的错误操作。(3)Grounding:即使模型的规划正确,执行的动作也可能与其规划过程不一致,主要表现为鼠标点击错误。
- PC Agent-E 改进主要源于长期规划能力的提升。训练后的 PC Agent-E 生成的思考过程明显更长,并在验证、反思和自我修正方面表现出更强的推理能力。
- Qwen2.5-VL-72B 和 PC Agent-E 有时也会因 Grounding 和 Knowledge 问题而出现失败。
2.3.2. 验证 Trajectory Boost 效果的训练时期的动作增强
在训练过程中改变所使用的合成动作数量,并评估模型性能。
- 结果
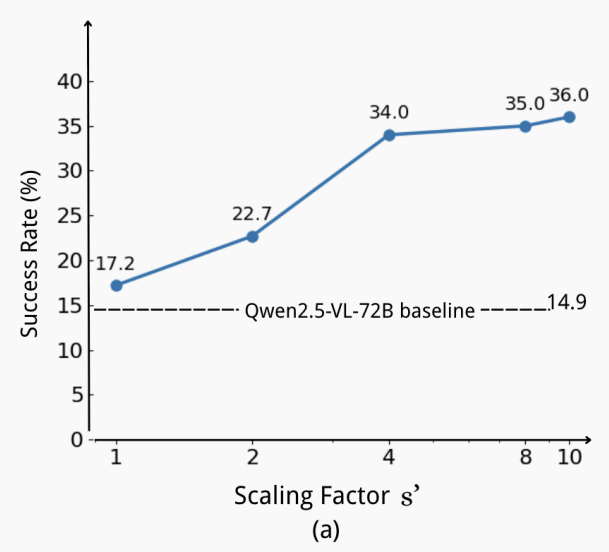
- 结论
随着动作决策数量的增加,模型性能显著提升。与仅基于人类轨迹训练相比,PC Agent-E 实现了显著更高的增益。
2.3.3. 测试时期的动作增强
评估该模型在任务执行过程中允许的最大步数情况下的区别。
- 结果
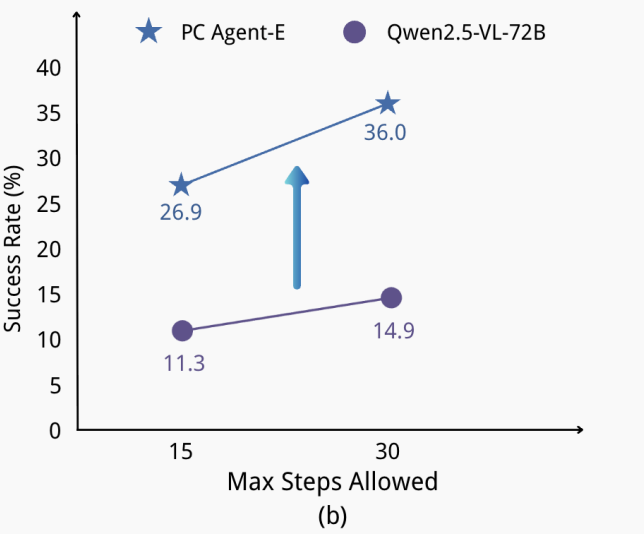
- 结论
PC Agent-E 在测试阶段能更好地利用更长的执行时间(执行动作的步数),表现出更强的适应性和修复能力。
2.3.4. 跨平台的泛化能力(OSWorld)
- 结果
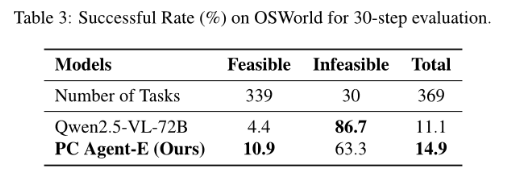
- 分析
(1)PC Agent-E 具有强大的跨平台泛化能力。
(2)不可行的攻击(infeasible hacking)。较弱的 Qwen2.5-VL-72B 模型在不可行任务上表现出显著更好的性能。表明当前对不可行任务的评估方法并未准确反映计算机使用代理的能力。未来的研究可以着眼于设计更强的不可行任务评估标准,包括评估代理在声明任务为不可能时的理由,以尽量减少利用性行为。