https://www.arxiv.org/abs/2510.06727
现有问题
- LLM 在处理长周期、多轮任务时面临着根本性的可扩展性瓶颈。
- 使用 RL 训练 LLM 智能体进行涉及外部工具的扩展交互时,对话历史、工具观察和推理轨迹的积累会迅速填满模型的上下文窗口。
解决方案
- SUPO算法:周期性地将工具使用历史压缩成由LLM生成的简洁、任务相关的摘要,然后将工作上下文重置为初始提示加上这个任务相关的摘要。
- SUPO 算法是 model-free 的 policy 方法,在 online RL 设定下,使用 终局 奖励,通过 token-level 优化,主要解决 LLM多轮RL训练中上下文长度迅速成为瓶颈,导致指令遵循能力下降、rollout成本过高以及严格的上下文限制。
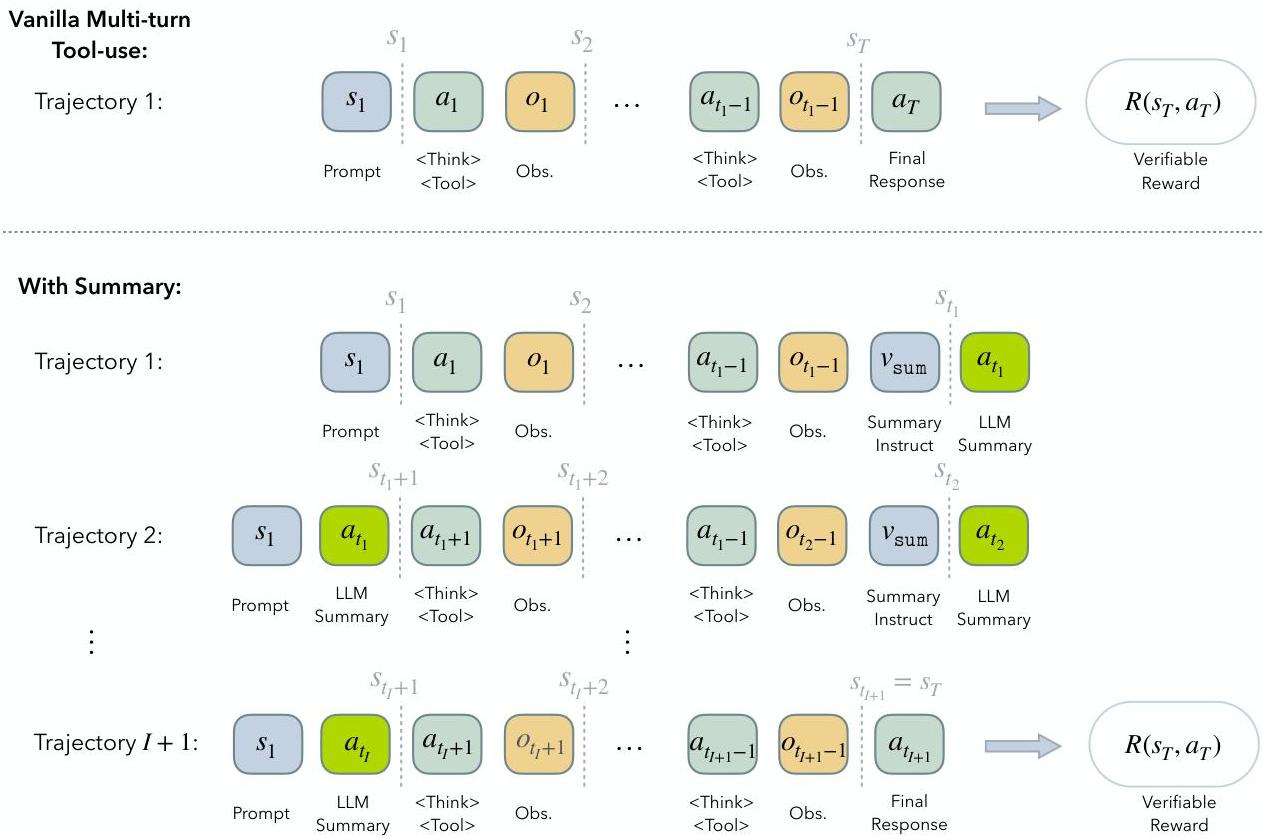
End-to-end RL Training of Agent with Summarization (代理与 summarization 的端到端RL训练)
“基于摘要的上下文管理”策略
问题:LLMs在处理多轮交互或复杂任务时,其理解和生成能力会受到自身固定上下文窗口大小的限制。当交互历史累积过多时,LLM可能“忘记”早期信息,导致推理错误,同时处理长文本也会显著增加计算成本。
根本目的:在不修改LLM底层架构的情况下,让它能有效处理比其原生上下文窗口更长的任务。
关键机制:LLM自我学习生成“任务相关”的摘要。
- 作者认为总结本身也是LLM可以学习到的一种行为,因此可以在强化学习训练过程中,让LLM不仅学习如何使用工具完成任务,还同时学习如何生成高质量的摘要。
- 高质量的摘要意味着它能够识别任务相关信息(哪些历史细节对于后续步骤至关重要?)、抽象和概括(如何用最简洁的语言表达这些关键信息?)、丢弃不相关信息(哪些细节现在已经不重要了,可以安全地移除?)
- 这种“学习到的总结”使得摘要能够动态适应具体任务的需求,而不仅仅是简单地截断上下文,也不是使用预设规则进行总结。
SUPO算法
SUPO(Summarization augmented Policy Optimization,摘要增强策略优化)算法旨在解决LLM在执行长周期、多轮任务时面临的上下文长度限制问题,尤其是在通过RL进行微调时。
核心思想: 让LLM智能体学会自主地、端到端地管理其上下文,通过生成任务相关的历史摘要来突破固定的上下文窗口限制。它将摘要生成本身视为RL策略的一部分进行优化,确保智能体不仅学会如何执行任务,还学会如何高效地记住和遗忘信息。
SUPO是GRPO风格的策略梯度算法。奖励是稀疏的二元奖励(成功为1,失败为0)。
目标:
- 使LLM智能体能够处理远超其固定上下文窗口长度的长周期任务。
- 在保证甚至提升任务成功率的同时,有效控制或降低实际工作上下文长度。
- 通过端到端训练,联合优化工具使用行为和上下文摘要策略。
摘要增强型MDP(修改状态转换)
SUPO将标准MDP扩展为摘要增强型MDP(Summarization-augmented MDP)。
在LLM智能体的标准MDP中,任何步骤的状态通常是所有先前提示、行动和观察的拼接。随着智能体行动,状态单调增长。然而,在摘要增强的MDP中,状态转换被修改:智能体仍然将其行动和观察附加到当前状态,但如果生成的上下文长度超过预定义阈值,则会触发摘要步骤。模型被提示生成摘要,下一个状态变为仅包含初始提示和新摘要的压缩表征。这样,就可以把一个超长轨迹拆分为数个短轨迹。
状态转换由以下规则定义:
- 若上下文未超限 ($|(s_t, a_t, o_t)| < L$) 且未收到总结指令 ($v_{sum} \not\subseteq s_t$) 的情况,状态正常增长;
- 若对应上下文超限 ($|(s_t, a_t, o_t)| \geq L$) 但未收到总结指令 ($ v_{sum} \not\subseteq s_t $) 的情况,状态将附加总结指令 $v_{sum}$,准备进行总结;
- 若已收到总结指令 ($v_{sum} \subseteq s_t$) 的情况,此时 $a_t$ 是生成的摘要,下一个状态将被压缩为初始提示 $s_1$ 和摘要 $a_t$。
于是一个长周期轨迹被分解为多个子轨迹,每个子轨迹以对过去的摘要(或初始提示)开始,以智能体为当前工作片段生成新摘要结束。

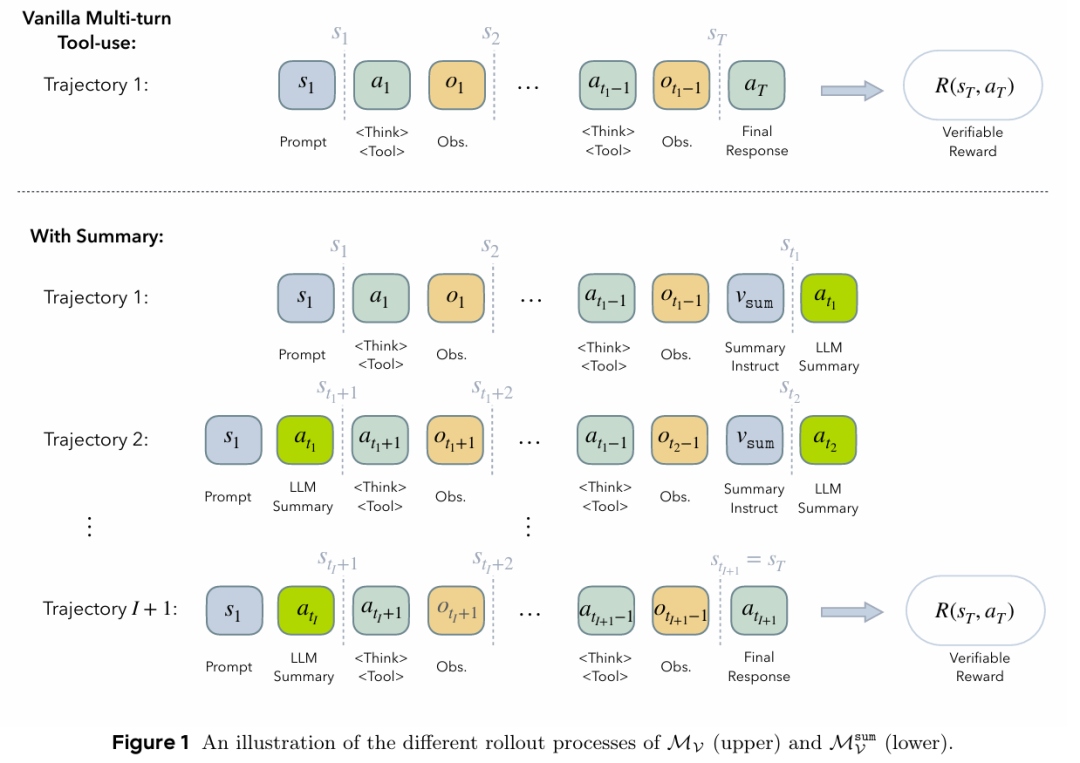
图1:
- 上图(Vanilla Multi-turn Tool-use)代表传统的LLM多轮工具使用方法。在每次交互中,LLM会接收一个状态s(prompt),根据这个状态进行思考(Think)并做出动作a,即采取某个工具(Tool)。工具执行后会产生一个观察结果o。 这些所有的信息(prompt、LLM输出、工具观察和推理痕迹)会不断地被累积,形成下一个状态s。这个过程一直持续到LLM给出最终响应a_T或达到最大步数H。 这种方法的主要问题是上下文会随着轮次增加而迅速增长,最终达到LLM的固定上下文窗口限制,导致“上下文长度限制”问题。
- 下图(With Summary)是论文的带有“摘要式上下文管理”的方法。在上下文长度达到预设的“摘要阈值”(L)后,LLM会被指示生成一个过去交互的摘要(v_sum)。一旦摘要生成,工作上下文就会被重置为初始提示(s_1)和这个新的摘要(a_t1)。这意味着模型不再需要携带完整的历史记录,从现在开始相当于处理一个新的“子轨迹”。
策略梯度表示
修改后的状态转换使得上下文能够周期性重置,因此需要对应地修改策略梯度表示。论文的定理 3.2 将一个长周期轨迹的策略梯度分解为多个摘要子轨迹梯度的求和。这使得SUPO能够利用现有的RL基础算法(如PPO、GRPO)进行训练,因为每个子轨迹可以被视为一个独立的、短期的MDP推出。

单条子轨迹的策略梯度 = 该子轨迹下执行步骤(优化工具使用)的策略梯度+该子轨迹下总结步骤(优化当前轨迹总结)的策略梯度。
算法设计细节
-
过长轨迹掩码机制(Overlong Trajectory Masking):用于处理那些在达到摘要阈值前就变得过长的轨迹,进一步稳定训练。
- 核心思想: 将“过长轨迹”定义为那些在达到最大步数 $ H $ 或最大总结次数 $ S $ 之前,未能给出最终响应的“失败的”长轨迹。这些过长轨迹会在计算梯度时被mask掉,不参与损失函数的计算。
- 原因:避免训练偏差。作者解释说:“如果没有掩码,目标可能会偏向于抑制那些表现出良好总结策略但未能在步数或轨迹限制内提供答案的长Rollouts。”
- 消融实验见论文第5.2.2节。
-
上下文长度的精细控制:为防止非常长的观察将上下文远远推过摘要阈值,SUPO在生成摘要前丢弃最后的行动-观察对。这确保用于摘要的上下文长度保持在严格控制的范围内。
- 实际情况:理论上(Proposition 3.1)最大工作上下文长度为 $L + 2L_A + L_O + |v_{sum}|$,其中 $L_O$ 是来自工具返回的最大token数。但在复杂任务中$L_O$ 可能会非常长,导致实际上下文长度 $L_t$ 远远超过总结阈值 $L$。
- 处理方式:当检测到上下文长度 $L_t > L$ 并决定进行总结时,SUPO会丢弃最后一个(action, observation)。即,对于刚刚产生的 (action, observation),系统不将此加入上下文并进行总结,反而舍弃,然后将总结指令
v_sum加入,准备让模型对舍弃了最后一步的上下文进行总结。
-
轨迹管理:将一个带有摘要的完整推出视为一系列的“子轨迹”,每个子轨迹都是独立的MDP推出,方便集成到现有RL基础设施。
-
组相对优势估计(GAE):SUPO使用GAE稳定优化并鼓励探索,而非简单地使用全局或单个子轨迹的均值。
Experiments Results
环境任务
- CodeGym
- https://www.alphaxiv.org/abs/2509.17325
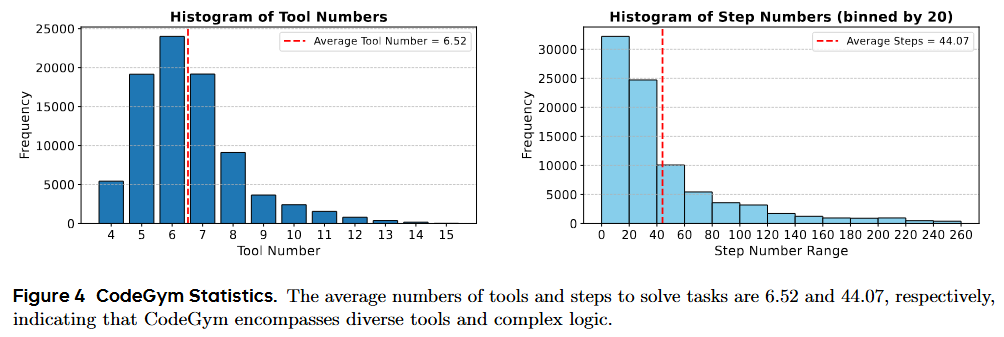
- CodeGym 将编程问题转化为交互式的多轮工具使用环境,强调多回合工具使用环境,LLM智能体必须调用抽象工具来通过单元测试。
- CodeGym 的任务通常平均要求模型调用 44.07 次工具。
- BrowseComp-Plus
- https://www.alphaxiv.org/abs/2508.06600
- BrowseComp-Plus 提供固定的、人工筛选的文档语料库,让智能体使用提供的搜索工具来回答复杂问题,并评估其答案准确性、搜索调用次数和引用质量。
- 这些查询需要迭代搜索规划和对搜索结果的推理,并且需要复杂的、多轮查询交互。专有模型(如gpt)的搜索调用次数平均超过20次。
评估指标
- 总结率(Summarization Rate):衡量Rollouts中有多少比例触发了总结。
- 条件成功率(Conditional Success Rate):衡量在触发总结的Rollouts中,有多少比例最终成功。
对比实验:SUPO的有效性
指标
- Working len. ↓:一个时间步内,模型实际加载到内存中的上下文的最大长度。
- Effective len. ↑:模型在整个长程任务中能够“有效地”利用和记住的信息总量。在SUPO中通过【工作上下文长度 * (最大总结次数 + 1)】来近似衡量。
实验结果:证明了SUPO的有效性。
- CodeGym:SUPO能够实现比使用32K上下文的基线更高的成功率,而SUPO本身仅使用4K工作上下文。
- BrowseComp-Plus:SUPO实现了 53.0% 的最终成功率。
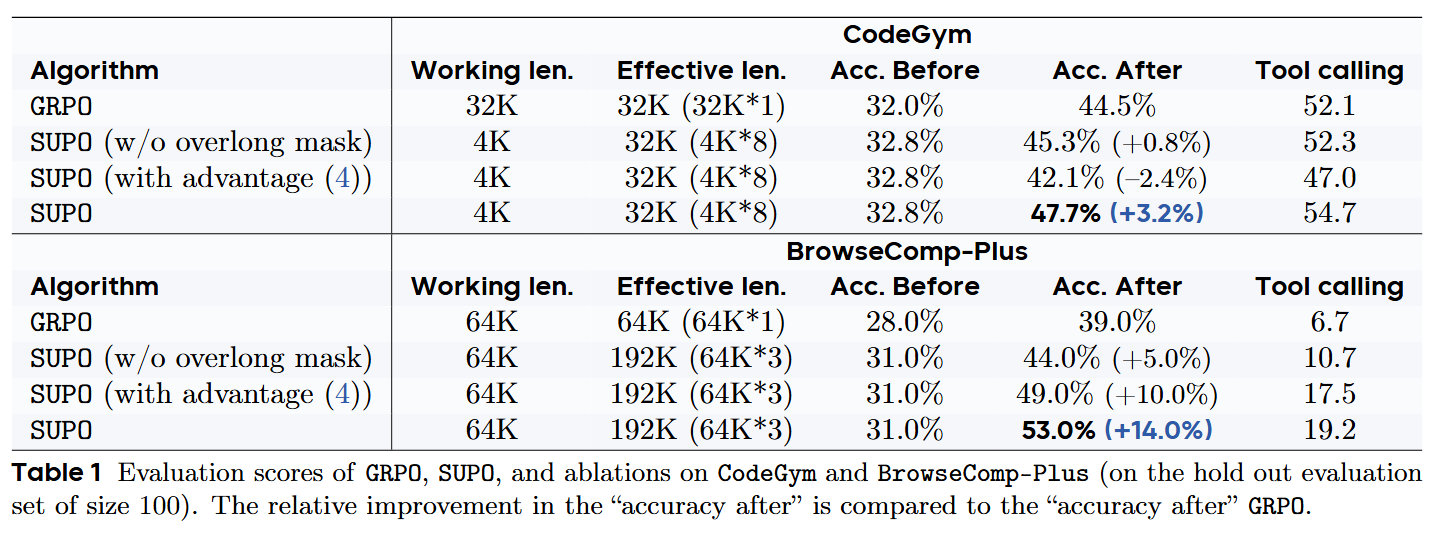
消融实验:过长轨迹的掩码机制
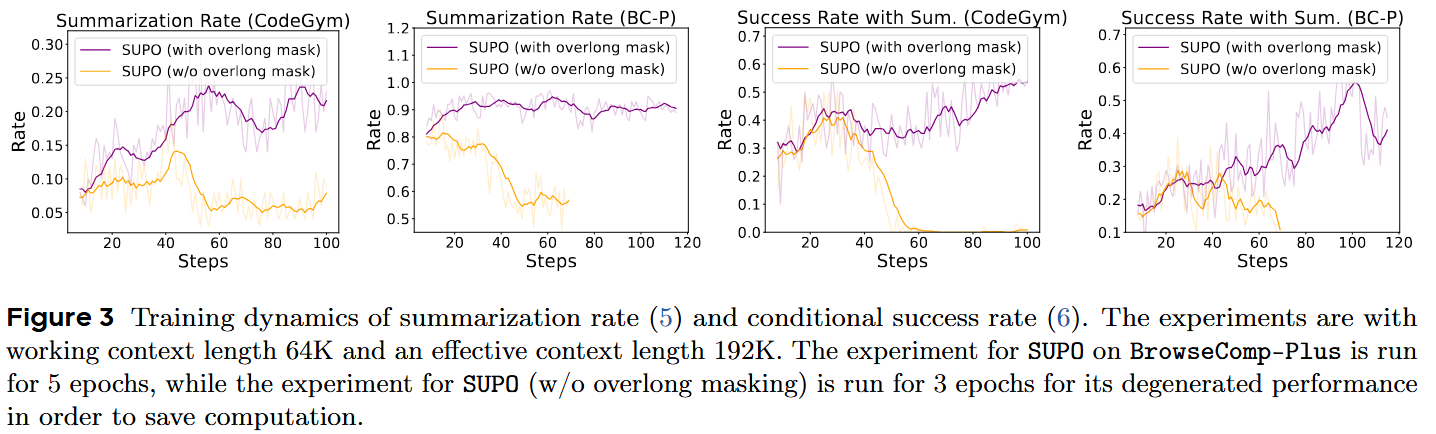
实验设计:SUPO with overlong mask(包含过长轨迹mask机制的标准SUPO)和 SUPO w/o overlong mask(移除了过长轨迹mask机制的SUPO版本)在CodeGym和BrowseComp-Plus实验对比。
实验结果和发现:过长轨迹的掩码机制是必要的。
-
对于两个任务,没有过长mask机制的SUPO显示出了所谓“总结模式的崩溃”:
- 总结率显著下降:更多的Rollouts倾向于在一个单一轨迹中完成,这与通过总结来扩展有效上下文的初衷背道而驰。模型不再倾向于利用总结机制。
- 条件成功率骤降至0:这表明在没有掩码的情况下,即使有Rollouts触发了总结,它们也无法有效地引导模型走向成功,总结变得无效。
情况分析:工具调用
在BrowseComp-Plus中对SUPO、GRPO以及不采用超长掩码的SUPO实验。
- 平均而言,与GRPO相比,SUPO在训练期间允许并激励的工具调用次数最多可达3倍。对于BrowseComp-Plus而言,能够利用工具搜索更多相关资讯对于提升模型性能至关重要。
- 尽管也对GRPO应用了超长掩码,以屏蔽那些在64K上下文长度内未能给出最终响应的轨迹,但GRPO的平均工具调用次数仍在下降。
- 不采用超长掩码的SUPO,其平均工具调用次数相较于采用超长掩码的SUPO出现了快速下降。

情况分析:在测试时扩展到处理更多轮摘要
能否将由SUPO训练、具有最大摘要数量S的模型直接扩展到一个最大摘要数量S'>S的智能体?如果智能体学会了一种真正可泛化的摘要策略,那么它应该能够重复应用该策略来解决需要更长历史的更复杂问题。因此,作者还在BrowseComp-Plus上以最多次摘要训练的模型,在测试时以允许增加的摘要轮数进行评估。
实验结果:使用SUPO训练的模型的准确率不仅超过了所有基线,而且随着测试时允许的摘要轮数增加而持续增长。
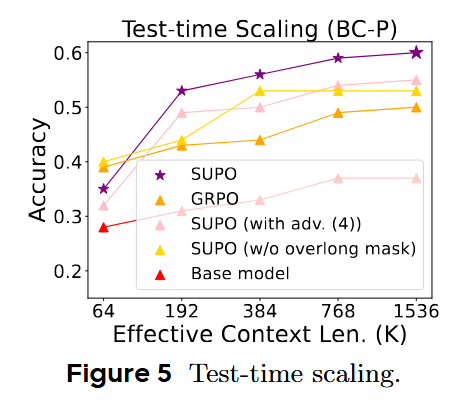
这表明SUPO所做的不仅仅是管理内存限制;它赋予了智能体一种稳健、可扩展的推理能力。通过学习将其经验提炼成有效的摘要,智能体可以动态扩展其问题解决范围,应对远比其明确训练过的任务更复杂的挑战。