Overview
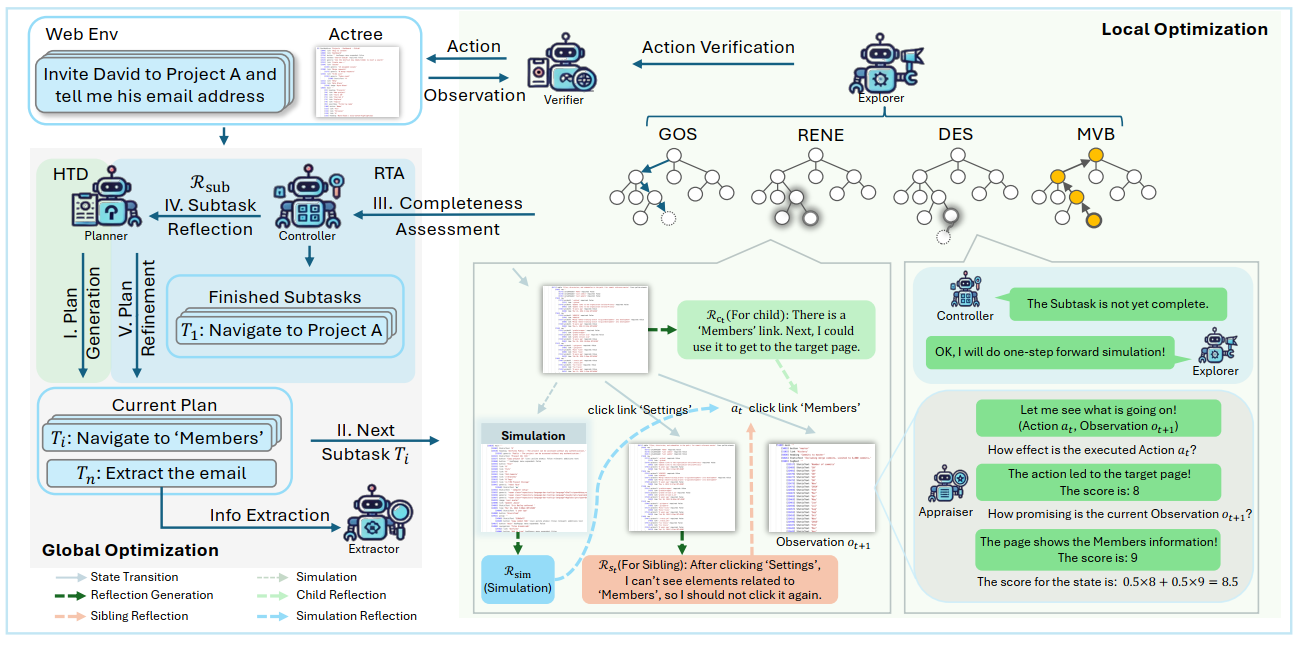
Global Optimization(全局优化)
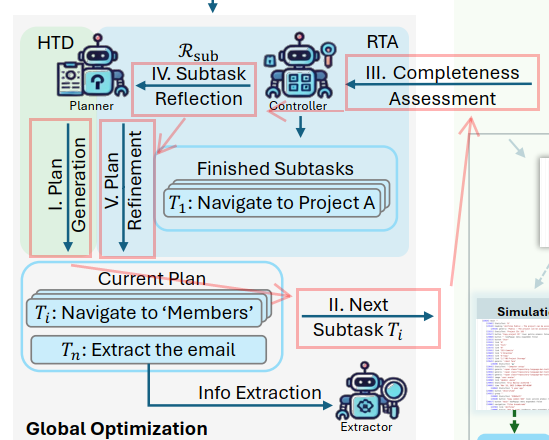
I. Plan Generation (计划生成)
Planner把宏观的用户指令分解为多个子任务。
执行工作的智能体:Planner
输入:宏观的用户指令(邀请David进入项目A并告诉我他的邮箱地址)和少量的“高层次演示示例”。
输出:多个子任务P = {T₁, T₂, ..., Tₙ}。
II. Next Subtask Ti (下一个子任务 Ti) <分支判断点>
系统开始按顺序处理每个子任务。
- 如果Ti是信息提取任务(如Extract the email)
流程跳转到Info Extraction。Extractor直接从当前页面的 Actree 中查找并提取所需的信息,然后将结果返回给 Controller 进行评估。
智能体:Extractor
输入:当前的子任务 Ti 和当前环境的状态 o_t(即最新的 Accessibility Tree)。
输出:提取出的具体信息。
该结果随后被传递给 Controller 进行下一步的**III. Completeness Assessment**。
- 如果Ti是操作任务(如Navigate to 'Members')
流程会进入右侧 Local Optimization (局部优化) 阶段,启动一个完整的 MCTS 循环(GOS → RENE → DES → MVB),直到满足终止条件(如达到最大节点数 nmax 或被 Controller 主动终止)。
智能体:Explorer, Verifier, Appraiser, Controller
输入:当前的子任务 Ti 和当前环境的状态 o_t。
输出:执行了一系列动作后的最新状态 o_t+1。
Local Optimization (局部优化)
在后文中会具体介绍Local Optimization的工作流程,这里仅介绍图1中RENE和DES的部分。
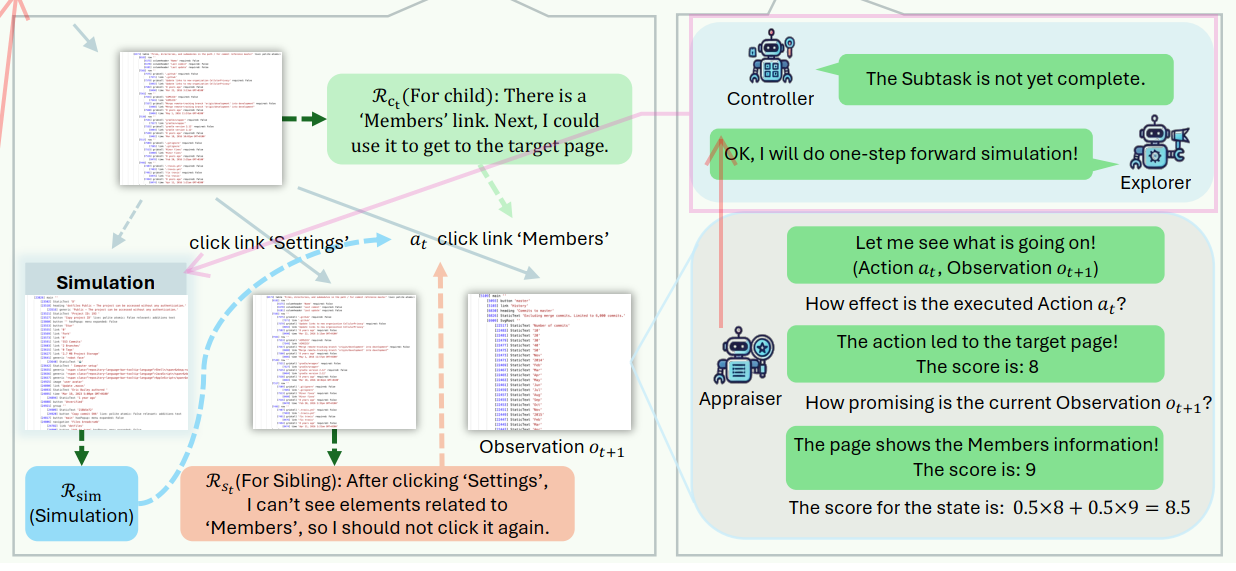
RENE
执行动作并评估,生成反思。
智能体:Explorer
输入:动作 aₜ。
过程:
- 通过自动化工具在真实浏览器环境中执行该动作(不是模拟);
- 比较执行前后的状态变化,判断动作是否达到了预期效果。
- 根据动作效果进行思考,生成反思。
输出:生成两种反思。
- Child Reflection (Rct):
"There is a 'Members' link. Next, I could use it to get to the target page."
生成时机:无论动作成功与否,只要观察到有用信息。
目的:为当前路径的下一次扩展提供方向,维持思维链连贯性。 - Sibling Reflection (Rst):
"After clicking 'Settings', I cn't see elements related to 'Members', so I should not click it again."
生成时机:当动作未达到预期效果时。
目的:警告其他可能路径(兄弟节点)避免重复错误。
DES
Step 1:动作潜力评估
智能体:Appraiser
输入:
- 动作效果 Effect(at)(来自RENE阶段)
- 新的状态 ot+1(来自RENE阶段)
- 当前子任务 Ti
过程:计算状态的总价值。
评估动作效果Seff(at)和评估未来潜力Sfut(ot+1)。
输出: - 评估动作效果 Seff(at):"The action led to the target page! The score is:8"
- 评估未来潜力 Sfut(ot+1):"The page shows the Members information! The score is:9"
Step 2:计算状态总价值与Q值更新
智能体:无(系统内部计算)
输入:Seff(at) 和 Sfut(ot+1)
过程:计算加权总价值:Stotal(at, ot+1) = weff · Seff(at) + wfut · Sfut(ot+1),该值也为Q值。
输出:总价值 Stotal(Q值)。
Step 3:动作完成度评估与前向模拟
智能体:Controller, Explorer
输入:当前子任务 Ti,已执行的动作序列 Ht+1 和当前状态 ot+1
过程:
- Controller判断是否完成子任务,当判断为未完成时,执行一步前向模拟。
- Explorer一步前向模拟(仅当子任务未完成时执行),进行纯文本预测(非真实执行);
输出:若状态未完成,则生成 Rsim。
III. Completeness Assessment (完成度评估)
如果Ti是信息提取任务(如Extract the email),则判断这个操作类子任务是否完成;如果Ti是信息提取任务(如Navigate to 'Members'),则在 Extractor 完成信息提取后,Controller 会评估提取到的信息是否满足要求。
无论是哪种情况,如果完成,则把Ti放入Finished Subtasks里,否则生成对失败原因的分析,并执行IV。
智能体:Controller
输入:当前正在执行的子任务 Tᵢ、已执行的动作序列 {a₁, a₂, ..., aₜ}、以及最新的环境观察 oₜ₊₁。
输出:二元判断结果 Compₜ(完成或未完成)。
IV. Subtask Reflection (子任务反思)
当上一步Controller判断该子任务未完成时,此步骤被触发,用于学习经验教训。
智能体:Controller
输入:子任务 Tᵢ 的目标、执行过的动作序列、最终的观察结果 oₜ₊₁,以及Controller对失败原因的分析。
输出:一条文本形式的反思 R_sub。
V. Plan Refinement (计划精炼)
Planner利用 IV 阶段Controller产生的反思,对原始计划进行动态修正。
输入:Planner
输出:一个经过更新和改进的新计划P = {T₁', T₂', ..., Tₙ'}。
Global Optimization(局部优化:MCTS)
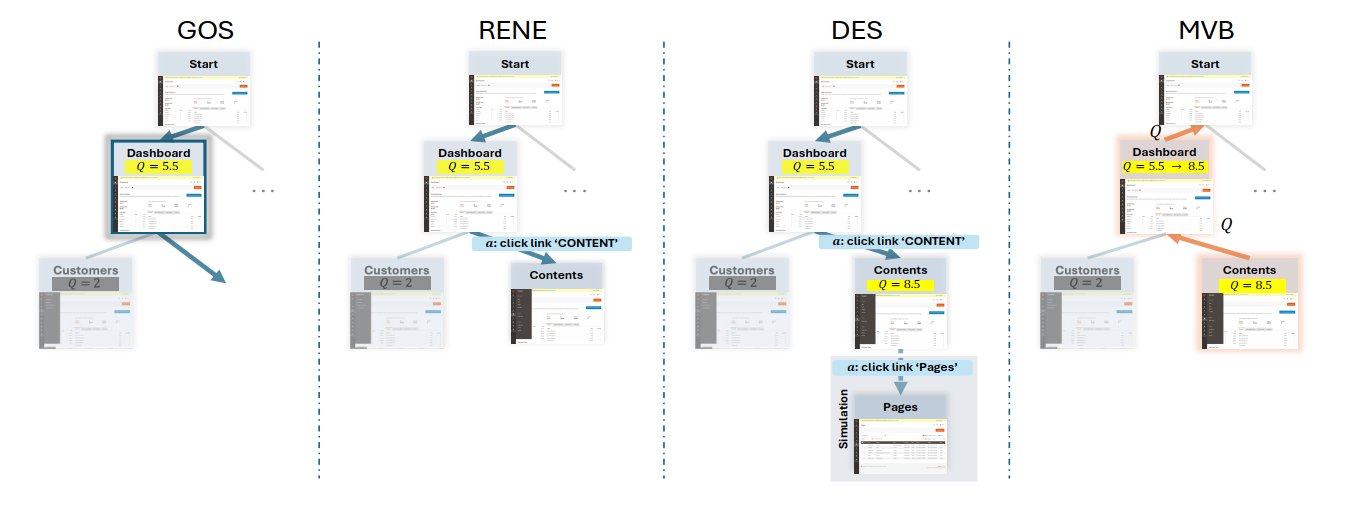
GOS (Goal-Oriented Selection)
Explorer基于LLM直觉和修改的PUCT公式从过滤后的动作空间中选择最有希望的动作。
智能体:Explorer
输入:
- 当前观察 ot (当前网页的状态)
- 当前子任务 Ti
- 历史动作 Ht
- 反思信息 Rt (包含战术反思和战略反思)
- 延续性推理 Ct-1
过程:利用LLM先验知识筛选最有希望的路径,并利用PUCT公式选择其中最有希望的动作。
输出:一个具体的动作 at 和该动作对应的意图 It。
RENE (Reflection-Enhanced Node Expansion)
Explorer在真实浏览器环境中执行动作,输出新状态、生成反思(子节点和兄弟节点)。
Step 1:接收动作并验证
智能体:Verifier
输入:GOS 阶段选定的动作 aₜ 和意图 Iₜ。
过程:
- 首先检查动作格式是否正确;
- 确认该动作在兄弟节点中没有重复,避免重复尝试相同动作。
输出:验证通过的动作,准备执行。
Step 2:执行动作并获取新状态
智能体:Explorer
输入:验证通过的动作 aₜ。
过程:
- 通过自动化工具在真实浏览器环境中执行该动作(不是模拟);
- 捕获执行后的环境变化。
输出:新的状态 (sₜ₊₁, oₜ₊₁),其中 oₜ₊₁ 是新的 Accessibility Tree。
Step 3:评估动作效果
智能体:Explorer
输入:旧状态 oₜ、新状态 oₜ₊₁、原始意图 Iₜ。
过程:
- Explorer 比较执行前后的状态变化;
- 判断动作是否达到了预期效果。
输出:动作效果 Effect(aₜ)。
Step 4:生成战术反思
智能体:Explorer
输入:动作效果 Effect(aₜ)、子任务 Tᵢ、目标状态。
过程:根据动作效果进行思考,生成反思。
输出:生成两种反思。
-
Child Reflection (Rct):
"There is a 'Members' link. Next, I could use it to get to the target page."
生成时机:无论动作成功与否,只要观察到有用信息。
目的:为当前路径的下一次扩展提供方向,维持思维链连贯性。 -
Sibling Reflection (Rst):
"After clicking 'Settings', I can't see elements related to 'Members', so I should not click it again."
生成时机:当动作未达到预期效果时。
目的:警告其他可能路径(兄弟节点)避免重复错误。
DES (Dynamic Evaluation and Simulation)
Appraiser评估动作效果和状态潜力,计算得分;Explorer进行一步前向模拟预测结果,输出状态总价值Stotal(Q值)和Simulation Reflection Rsim。
step 1:动作潜力评估
智能体:Appraiser
输入:
- 动作效果 Effect(at)(来自RENE阶段)
- 新的状态 ot+1(来自RENE阶段)
- 当前子任务 Ti
过程:计算状态的总价值。
评估动作效果Seff(at)和评估未来潜力Sfut(ot+1)。
输出:
- 评估动作效果 Seff(at):"The action led to the target page! The score is:8"
- 评估未来潜力 Sfut(ot+1):"The page shows the Members information! The score is:9"
Step 2:计算状态总价值与Q值更新
智能体:无(系统内部计算)
输入:Seff(at) 和 Sfut(ot+1)
过程:计算加权总价值:Stotal(at, ot+1) = weff · Seff(at) + wfut · Sfut(ot+1),该值也为Q值。
输出:总价值 Stotal。
step 3:动作完成度评估
智能体:Controller
输入:当前子任务 Ti,已执行的动作序列 Ht+1 和当前状态 ot+1
过程:判断是否完成子任务。
输出:二元判断结果 Ct(完成/未完成)。当判断为未完成时,执行一步前向模拟。
step 4:一步前向模拟(仅当子任务未完成时执行)
智能体:Explorer
输入:当前状态 ot+1,子任务 Ti和二元判断结果 Ct(未完成)。
过程:
- 生成模拟动作 at+1sim 和意图 It+1sim, LLM进行纯文本预测(非真实执行);
- 生成 Simulation Reflection (Rsim),指导下一轮MCTS的GOS。
输出:生成 Rsim。
MVB (Maximal Value Backpropagation)
系统将叶节点的Q值沿路径回溯,使用最大值策略更新祖先节点的Q值。
智能体:Controller
输入:所有子节点的状态及其Q值 Q(st+1)
目的:反向传播扩展节点奖励,使用最大值策略。
输出:父节点更新后的Q值,计算方式为 max Q(st+1)
具体数值设置
| 参数类别 | 参数名称 / 描述 | 具体数值 / 设置 | 说明 |
|---|---|---|---|
| 搜索控制参数 | 最大节点数(Max node count per subtask, nmax) |
10 | 每个子任务最多扩展 10 个节点 |
探索偏置(Exploration bias, wpuct) |
5 | 平衡探索与利用,用于 GOS 中的 PUCT 公式 | |
| 搜索深度限制(Search depth limit) | 5 | MCTS 树最大深度为 5 层 | |
| 分支数(Number of branches) | 3 | 每个节点最多扩展 3 个子节点,基于 LLM 初始直觉通常不超过 3 个相关元素 | |
| 奖励机制参数 | 动作有效性权重(weff) |
未明确给出 | 用于奖励函数 Stotal = weff·Seff + wfut·Sfut,平衡动作有效性 |
未来潜力权重(wfut) |
未明确给出 | 同上,平衡未来状态潜力 | |
| 评分范围 | 0–10 分制 | Seff 和 Sfut 均使用细粒度 0–10 评分 | |
| LLM 配置(影响 MCTS) | 使用模型 | GPT-3.5-turbo-0125 / GPT-4o-2024-05-13 | 作为 MCTS 中各智能体(Explorer、Appraiser 等)的推理引擎 |
| Temperature | 0.3 | 控制 LLM 生成的随机性 | |
| 最大 token 数 | 4096 | 上下文长度限制 |
✅ 来源:主要来自论文 Section 4.1 “Experimental Setup” 与 Appendix B.3 “Implementation Details”,以及 Appendix C.1 对超参数影响的说明。
反思机制
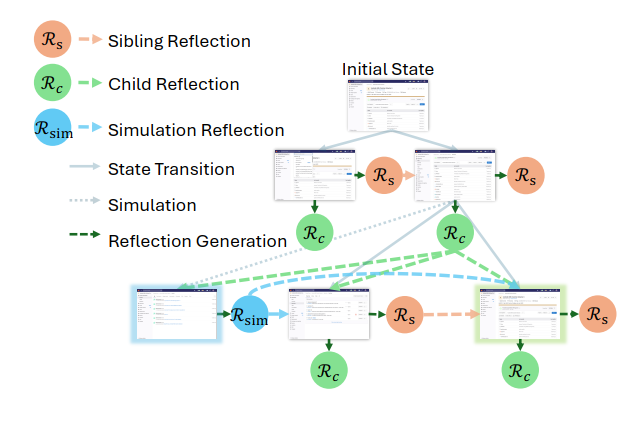
1. Child Reflection (Rct) - 子节点反思
- 触发时机:在 RENE 阶段,当一个动作被执行并产生新状态后。
- 生成过程:Explorer 分析当前状态
ot+1,思考“下一步我应该做什么?”。 - 目的:为当前路径的下一个子节点提供方向性指引,确保思维链的连贯性。
- 工作原理:
- 如图所示,
Rct会成为下一个节点的Parent Reflection (Rpt)。 - 这保证了决策过程的连续性,让智能体不会忘记之前的思路。
- 如图所示,
2. Sibling Reflection (Rst) - 兄弟节点反思
- 触发时机:在 RENE 阶段,当某个动作被证明无效或偏离目标时。
- 生成过程:Explorer 识别到当前动作未能达到预期效果,并生成一条警告。
- 目的:警告同一层级的其他可能动作(即兄弟节点)避免重复同样的错误。
- 工作原理:
- 当 MCTS 尝试其他备选动作时,
Rst会被作为输入,告诉系统“不要走这条路”。 - 这极大地提高了搜索效率,防止智能体陷入死循环。
- 当 MCTS 尝试其他备选动作时,
3. Simulation Reflection (Rsim) - 模拟反思
- 触发时机:在 DES 阶段,进行一步前向模拟之后。
- 生成过程:Explorer 对新状态
ot+1进行预测,思考“如果我现在执行下一步,会发生什么?”。 - 目的:评估当前状态的未来潜力,为节点打分提供依据。
- 工作原理:
Rsim是一次低成本的“思维实验”,不消耗任何真实资源。- 它帮助 Appraiser 计算
Sfut(ot+1)(未来潜力),从而影响该节点的 Q 值。 - 如果模拟结果显示某条路径很有希望,系统就会优先探索它。